import pandas as pd
import numpy as np
import sqlite3
import matplotlib.pyplot as plt
from plotnine import *
from mizani.formatters import percent_format, comma_format, date_format
from itertools import product
from datetime import datetime, timedelta7 Compound Returns
In this chapter, we provide a treatment of compound returns. Whether constructing buy-and-hold portfolios, evaluating fund performance, computing cumulative wealth indices, or estimating long-horizon risk measures, the ability to correctly compound returns over arbitrary horizons is indispensable. We begin with the mathematical foundations: the distinction between simple and log returns, the relationship between arithmetic and geometric means, and the properties of continuously compounded returns. Along the way, we address practical complications that arise in real-world equity data, such as trading halts, price limit mechanisms, partial-period returns, and delisting events, and show how to handle them in the Vietnamese context.
The chapter proceeds to rolling compound returns over standard horizons (3, 6, 9, and 12 months), compound returns aligned to fiscal period ends, forward-looking cumulative returns for event studies, and rolling volatility estimation.
7.1 Simple Returns versus Log Returns
Before discussing compounding, we must distinguish between the two fundamental return conventions used in finance.
7.1.1 Simple (Arithmetic) Returns
The simple gross return on an asset from period \(t-1\) to \(t\) is defined as
\[ 1 + R_t = \frac{P_t + D_t}{P_{t-1}}, \tag{7.1}\]
where \(P_t\) denotes the price at the end of period \(t\) and \(D_t\) denotes any cash distributions (dividends, coupons) paid during period \(t\). The simple net return is \(R_t\) itself. When we speak of “returns” without qualification, we typically mean simple net returns.
The key property of simple returns is that multi-period compounding is multiplicative:
\[ 1 + R_t(k) = \prod_{j=0}^{k-1} (1 + R_{t-j}) = (1 + R_t)(1 + R_{t-1}) \cdots (1 + R_{t-k+1}), \tag{7.2}\]
where \(R_t(k)\) is the \(k\)-period compound return ending at time \(t\). This multiplicative structure is the foundation of all compounding methods discussed in this chapter.
7.1.2 Continuously Compounded (Log) Returns
The continuously compounded return, or log return, is defined as
\[ r_t = \ln(1 + R_t) = \ln\!\left(\frac{P_t + D_t}{P_{t-1}}\right). \tag{7.3}\]
The central advantage of log returns for compounding is that multi-period compounding becomes additive:
\[ r_t(k) = \ln(1 + R_t(k)) = \sum_{j=0}^{k-1} r_{t-j} = r_t + r_{t-1} + \cdots + r_{t-k+1}. \tag{7.4}\]
This additive property follows directly from the logarithmic identity \(\ln(ab) = \ln(a) + \ln(b)\). It is computationally convenient because summation is numerically more stable than iterated multiplication, and because many statistical procedures (means, variances, regressions) operate naturally on additive quantities.
To recover the simple compound return from the sum of log returns, we apply the exponential function:
\[ R_t(k) = \exp\!\left(\sum_{j=0}^{k-1} r_{t-j}\right) - 1. \tag{7.5}\]
7.1.3 When Do They Diverge?
For small returns, the approximation \(r_t \approx R_t\) holds to first order (via the Taylor expansion \(\ln(1+x) \approx x\) for \(|x| \ll 1\)). However, for large returns, which is common in emerging markets, small-cap stocks, or crisis periods, the two can diverge substantially. Consider a stock that doubles in price (\(R_t = 1.0\)): the log return is \(r_t = \ln(2) \approx 0.693\), a 31% discrepancy. Conversely, for a stock that loses half its value (\(R_t = -0.5\)): the log return is \(r_t = \ln(0.5) \approx -0.693\), which is 39% larger in magnitude.
This divergence is especially relevant in Vietnam, where daily price limits of \(\pm 7\%\) on HOSE, \(\pm 10\%\) on HNX, and \(\pm 15\%\) on UPCoM can produce sequences of limit-up or limit-down days. Over a week of consecutive limit-up days on HOSE, the simple return is \((1.07)^5 - 1 = 40.3\%\) while the log return is \(5 \times \ln(1.07) = 33.8\%\), which is a meaningful gap.
Table 7.1 illustrates this divergence across a range of return magnitudes.
simple_returns = [-0.50, -0.30, -0.15, -0.10, -0.07, -0.05, -0.01,
0.00, 0.01, 0.05, 0.07, 0.10, 0.15, 0.30, 0.50, 1.00]
comparison_df = pd.DataFrame({
"Simple Return": [f"{r:.2%}" for r in simple_returns],
"Log Return": [f"{np.log(1+r):.4f}" for r in simple_returns],
"Difference": [f"{np.log(1+r) - r:.4f}" for r in simple_returns],
"Relative Error (%)": [
f"{((np.log(1+r) - r) / abs(r) * 100):.2f}" if r != 0 else "—"
for r in simple_returns
]
})
comparison_df| Simple Return | Log Return | Difference | Relative Error (%) | |
|---|---|---|---|---|
| 0 | -50.00% | -0.6931 | -0.1931 | -38.63 |
| 1 | -30.00% | -0.3567 | -0.0567 | -18.89 |
| 2 | -15.00% | -0.1625 | -0.0125 | -8.35 |
| 3 | -10.00% | -0.1054 | -0.0054 | -5.36 |
| 4 | -7.00% | -0.0726 | -0.0026 | -3.67 |
| 5 | -5.00% | -0.0513 | -0.0013 | -2.59 |
| 6 | -1.00% | -0.0101 | -0.0001 | -0.50 |
| 7 | 0.00% | 0.0000 | 0.0000 | — |
| 8 | 1.00% | 0.0100 | -0.0000 | -0.50 |
| 9 | 5.00% | 0.0488 | -0.0012 | -2.42 |
| 10 | 7.00% | 0.0677 | -0.0023 | -3.34 |
| 11 | 10.00% | 0.0953 | -0.0047 | -4.69 |
| 12 | 15.00% | 0.1398 | -0.0102 | -6.83 |
| 13 | 30.00% | 0.2624 | -0.0376 | -12.55 |
| 14 | 50.00% | 0.4055 | -0.0945 | -18.91 |
| 15 | 100.00% | 0.6931 | -0.3069 | -30.69 |
Key takeaway: log returns are convenient for compounding (additive aggregation), but portfolio returns aggregate cross-sectionally in simple return space. In practice, we often transform to log returns for temporal compounding, then convert back to simple returns for reporting.
7.2 Mathematical Foundations of Compounding
7.2.1 Geometric Mean Return
The geometric mean return over \(T\) periods is
\[ \bar{R}_g = \left(\prod_{t=1}^{T} (1 + R_t)\right)^{1/T} - 1, \tag{7.6}\]
which represents the constant per-period return that would yield the same terminal wealth as the actual return sequence. It is always less than or equal to the arithmetic mean \(\bar{R}_a = \frac{1}{T}\sum_{t=1}^{T} R_t\), with equality only when all returns are identical. The relationship between the two is approximately:
\[ \bar{R}_g \approx \bar{R}_a - \frac{\sigma^2}{2}, \tag{7.7}\]
where \(\sigma^2\) is the variance of returns. This approximation, sometimes called the “volatility drag,” has important implications: high-volatility assets have a larger wedge between their arithmetic and geometric means, meaning their actual compound growth understates what a naive average would suggest. In a market like Vietnam’s, where individual stock volatility is often two to three times that of developed-market equities, the volatility drag can be substantial.
7.2.2 Wealth Index and Drawdowns
Given an initial investment of \(W_0\), the wealth at time \(T\) is
\[ W_T = W_0 \prod_{t=1}^{T} (1 + R_t). \tag{7.8}\]
The cumulative return (net) is simply \(W_T / W_0 - 1\). The maximum drawdown, a widely used risk measure, is defined as
\[ \text{MDD} = \max_{0 \le s \le t \le T} \left(\frac{W_s - W_t}{W_s}\right), \tag{7.9}\]
which measures the largest peak-to-trough decline in the wealth index. We will compute this quantity alongside compound returns below. Drawdowns are particularly informative in emerging markets that experience sharp corrections, as occurred during the global financial crisis of 2008 when the VN-Index fell roughly 66% from its 2007 peak.
7.2.3 Annualization
For a \(k\)-period compound return \(R_t(k)\) where each period has length \(\Delta\) (e.g., \(\Delta = 1/12\) for monthly data), the annualized return is
\[ R_{\text{ann}} = (1 + R_t(k))^{1/(k\Delta)} - 1. \tag{7.10}\]
Similarly, for volatility estimated from \(k\)-period returns with period length \(\Delta\):
\[ \sigma_{\text{ann}} = \sigma / \sqrt{\Delta}, \tag{7.11}\]
so monthly volatility is annualized by multiplying by \(\sqrt{12}\) and daily volatility by approximately \(\sqrt{252}\) (assuming 252 trading days per year). For Vietnam specifically, the HOSE typically has around 245–250 trading days per year after accounting for Vietnamese public holidays, which is close enough that the \(\sqrt{252}\) convention is standard.
7.3 Data Preparation
We start by loading monthly stock return data from our SQLite database. As prepared in previous chapters, this database contains monthly returns sourced from DataCore.vn for all securities listed on the Ho Chi Minh Stock Exchange (HOSE), Hanoi Stock Exchange (HNX), and the Unlisted Public Company Market (UPCoM). Returns are adjusted for stock splits, bonus issues, and rights offerings, and include reinvested cash dividends.
tidy_finance = sqlite3.connect(database="data/tidy_finance_python.sqlite")
prices_monthly = pd.read_sql_query(
sql="""
SELECT symbol, date, ret_excess, ret, mktcap, mktcap_lag, risk_free
FROM prices_monthly
""",
con=tidy_finance,
parse_dates=["date"]
).dropna()
factors_ff3_monthly = pd.read_sql_query(
sql="SELECT date, mkt_excess FROM factors_ff3_monthly",
con=tidy_finance,
parse_dates=["date"]
)
prices_monthly = prices_monthly.merge(
factors_ff3_monthly,
on="date",
how="left"
)
prices_monthly["ret_total"] = prices_monthly["ret"]
prices_monthly["mkt_total"] = (
prices_monthly["mkt_excess"] + prices_monthly["risk_free"]
)Let us inspect the sample:
print(f"Sample period: {prices_monthly['date'].min()} to "
f"{prices_monthly['date'].max()}")
print(f"Number of stocks: {prices_monthly['symbol'].nunique():,}")
print(f"Total observations: {len(prices_monthly):,}")
# print(f"Exchanges: {prices_monthly['exchange'].unique()}")Sample period: 2010-02-28 00:00:00 to 2023-12-31 00:00:00
Number of stocks: 1,457
Total observations: 165,499Table 7.2 provides summary statistics for the raw monthly returns, broken down by exchange. Differences across exchanges reflect the size and liquidity gradient: HOSE lists the largest and most liquid firms, HNX covers mid-cap companies, and UPCoM hosts smaller and more thinly traded securities.
sample_stats = (
prices_monthly
.groupby("exchange")["ret_total"]
.describe(percentiles=[0.05, 0.25, 0.50, 0.75, 0.95])
.round(4)
)
sample_stats7.4 Method 1: Cumulative Product via GroupBy
The most direct approach to compound returns uses the multiplicative property in Equation 7.2. For each security, we compute the cumulative product of gross returns \((1 + R_t)\) over the desired window.
def compute_cumret_cumprod(df, ret_col="ret_total",
group_col="symbol"):
"""Compute cumulative returns using cumulative product.
Parameters
----------
df : pd.DataFrame
Must contain `group_col`, 'date', and `ret_col`.
ret_col : str
Column name for period returns.
group_col : str
Column name for grouping (e.g., security identifier).
Returns
-------
pd.DataFrame
Original DataFrame augmented with 'cumret' and 'wealth_index'.
"""
df = df.sort_values([group_col, "date"]).copy()
df["gross_ret"] = 1 + df[ret_col]
df["wealth_index"] = (
df.groupby(group_col)["gross_ret"]
.cumprod()
)
df["cumret"] = df["wealth_index"] - 1
df.drop(columns=["gross_ret"], inplace=True)
return dfLet us apply this to the full sample and examine the resulting wealth indices for a few selected stocks:
stock_cumret = compute_cumret_cumprod(prices_monthly)
# Select stocks with long histories for illustration
stock_counts = (
stock_cumret.groupby("symbol")["date"]
.count()
.reset_index(name="n_obs")
)
long_history_stocks = (
stock_counts.nlargest(5, "n_obs")["symbol"].tolist()
)
sample_wealth = stock_cumret[
stock_cumret["symbol"].isin(long_history_stocks)
]Figure 7.1 plots the wealth indices (value of 1 VND invested) for these five securities over the full sample period.
plot_wealth = (
ggplot(sample_wealth, aes(x="date", y="wealth_index",
color="factor(symbol)")) +
geom_line(size=0.6) +
labs(
x="", y="Wealth index (1 VND invested)",
color="Stock"
) +
theme_minimal() +
theme(legend_position="bottom",
figure_size=(10, 5))
)
plot_wealth.draw()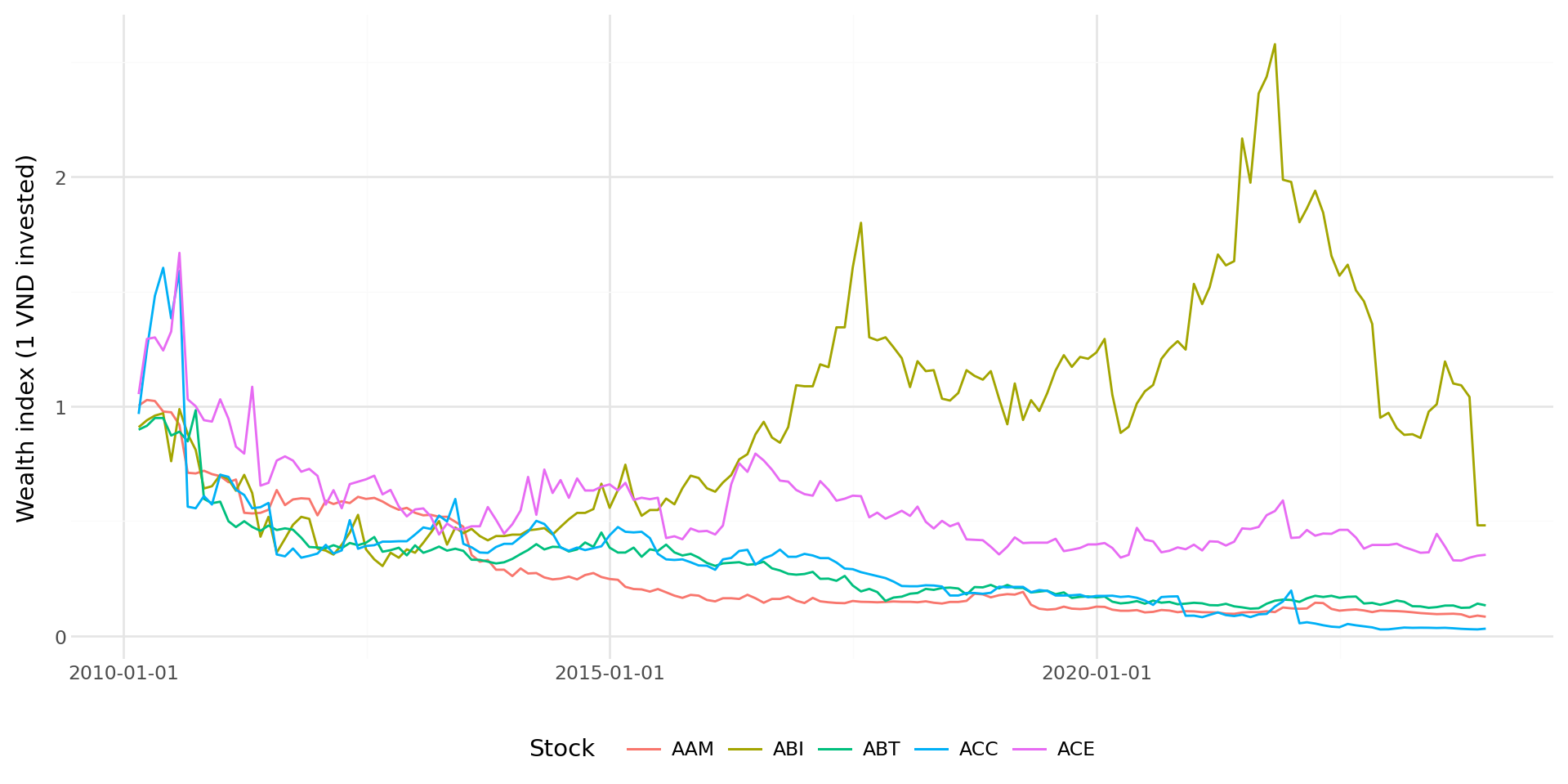
7.4.1 Handling Missing Returns
The cumulative product approach propagates missing values: if any \(R_t\) is NaN, the entire cumulative product from that point onward becomes NaN. This is conservative because it effectively assumes that a missing return renders the subsequent wealth index undefined. In many applications, this is the desired behavior because a missing return may indicate a data error or a period during which the stock was not trading.
However, in the Vietnamese market, missing returns can arise from extended trading halts. The State Securities Commission (SSC) and exchanges may suspend trading in a stock for various regulatory reasons, such as financial reporting delays, pending corporate restructuring announcements, or suspected market manipulation. These halts can last days, weeks, or even months. During such halts, the stock’s value has not changed (the last traded price remains the reference), so treating the missing return as zero (i.e., no price change) may be more appropriate than propagating NaN.
def compute_cumret_skipna(df, ret_col="ret_total",
group_col="symbol"):
"""Compute cumulative returns, treating missing returns as zero."""
df = df.sort_values([group_col, "date"]).copy()
df["gross_ret"] = 1 + df[ret_col].fillna(0)
df["wealth_index"] = (
df.groupby(group_col)["gross_ret"]
.cumprod()
)
df["cumret"] = df["wealth_index"] - 1
df.drop(columns=["gross_ret"], inplace=True)
return df
Warning
Treating missing returns as zero is an assumption that may or may not be appropriate. If returns are missing because the stock was halted, zero may be reasonable. If returns are missing due to data errors or because the stock was genuinely not trading (e.g., awaiting relisting after a corporate event), imputing zero can introduce bias. Always investigate the reason for missing values before deciding on a treatment.
7.5 Method 2: Log-Sum-Exp Approach
The log-sum-exp method exploits the additive property of log returns (Equation 7.4). This approach is particularly useful when computing compound returns over fixed windows (e.g., annual returns from monthly data) because summation is both computationally efficient and numerically stable.
def compute_cumret_logsum(df, ret_col="ret_total",
group_col="symbol",
date_col="date"):
"""Compute cumulative returns using the log-sum-exp approach.
Steps:
1. Transform to log returns: r_t = ln(1 + R_t)
2. Cumulative sum of log returns within each group
3. Exponentiate to recover simple cumulative return
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
date_col : str
Returns
-------
pd.DataFrame
"""
df = df.sort_values([group_col, date_col]).copy()
df["log_ret"] = np.log(1 + df[ret_col])
df["cum_log_ret"] = (
df.groupby(group_col)["log_ret"].cumsum()
)
df["wealth_index_log"] = np.exp(df["cum_log_ret"])
df["cumret_log"] = df["wealth_index_log"] - 1
df.drop(columns=["log_ret", "cum_log_ret"], inplace=True)
return dfLet us verify that the two methods produce identical results (up to floating-point precision):
stock_both = compute_cumret_cumprod(prices_monthly)
stock_both = compute_cumret_logsum(stock_both)
# Compare on non-missing observations
mask = (stock_both["cumret"].notna()
& stock_both["cumret_log"].notna())
max_diff = (stock_both.loc[mask, "cumret"] -
stock_both.loc[mask, "cumret_log"]).abs().max()
print(f"Maximum absolute difference between methods: {max_diff:.2e}")Maximum absolute difference between methods: 1.78e-14The difference is at the level of machine epsilon (\(\approx 10^{-15}\)), confirming numerical equivalence.
7.5.1 Period-Specific Compound Returns
A common task is to compute compound returns within calendar periods (months, quarters, years). The log-sum-exp approach lends itself naturally to grouped aggregation:
def compound_return_by_period(df, ret_col="ret_total",
group_col="symbol",
period="year"):
"""Compute compound returns within calendar periods.
Parameters
----------
df : pd.DataFrame
Must contain 'date' and `ret_col`.
period : str
One of 'year', 'quarter', 'month'.
Returns
-------
pd.DataFrame with compound returns per group-period.
"""
df = df.copy()
df["log_ret"] = np.log(1 + df[ret_col])
if period == "year":
df["period"] = df["date"].dt.year
elif period == "quarter":
df["period"] = df["date"].dt.to_period("Q")
elif period == "month":
df["period"] = df["date"].dt.to_period("M")
result = (
df.groupby([group_col, "period"])
.agg(
cumret=(
"log_ret",
lambda x: np.exp(x.sum()) - 1
),
n_obs=("log_ret", "count"),
n_miss=(ret_col, lambda x: x.isna().sum()),
start_date=("date", "min"),
end_date=("date", "max")
)
.reset_index()
)
return resultTable 7.3 shows annual compound returns for a subset of securities.
annual_returns = compound_return_by_period(
prices_monthly[
prices_monthly["symbol"].isin(long_history_stocks)
],
period="year"
)
recent_annual = (
annual_returns
.sort_values(["symbol", "period"])
.groupby("symbol")
.tail(5)
.round(4)
)
recent_annual.head(20)/tmp/ipykernel_2229780/2619242959.py:13: UserWarning: obj.round has no effect with datetime, timedelta, or period dtypes. Use obj.dt.round(...) instead.| symbol | period | cumret | n_obs | n_miss | start_date | end_date | |
|---|---|---|---|---|---|---|---|
| 9 | AAM | 2019 | -0.2810 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 10 | AAM | 2020 | -0.1622 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 11 | AAM | 2021 | 0.1250 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 12 | AAM | 2022 | -0.0913 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 13 | AAM | 2023 | -0.2337 | 12 | 0 | 2023-01-31 | 2023-12-31 |
| 23 | ABI | 2019 | 0.1946 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 24 | ABI | 2020 | 0.2418 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 25 | ABI | 2021 | 0.2896 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 26 | ABI | 2022 | -0.5085 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 27 | ABI | 2023 | -0.5042 | 12 | 0 | 2023-01-31 | 2023-12-31 |
| 37 | ABT | 2019 | -0.1893 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 38 | ABT | 2020 | -0.1400 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 39 | ABT | 2021 | 0.0842 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 40 | ABT | 2022 | -0.0789 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 41 | ABT | 2023 | -0.0768 | 12 | 0 | 2023-01-31 | 2023-12-31 |
| 51 | ACC | 2019 | -0.1875 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 52 | ACC | 2020 | -0.4923 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 53 | ACC | 2021 | 1.2339 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 54 | ACC | 2022 | -0.8538 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 55 | ACC | 2023 | 0.1027 | 12 | 0 | 2023-01-31 | 2023-12-31 |
Important
When the number of non-missing observations (n_obs) is less than 12 for an annual return, the compound return represents only a partial year. This commonly occurs in the first and last years of a security’s listing on HOSE, HNX, or UPCoM, or when a stock transfers between exchanges (e.g., from UPCoM to HOSE upon meeting listing requirements). Users should decide whether to retain or exclude such partial-year observations depending on their research design.
7.6 Method 3: Iterative Compounding with Retain Logic
In some applications, we need fine-grained control over how missing values, delisting events, or other special conditions affect the compounding process. The iterative approach processes each observation sequentially, carrying forward the cumulative return and applying conditional logic at each step.
def compute_cumret_iterative(df, ret_col="ret_total",
group_col="symbol",
handle_missing="carry"):
"""Compute cumulative returns iteratively with flexible
missing value handling.
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
handle_missing : str
'carry' : treat missing as zero return (carry forward)
'propagate' : propagate NaN (conservative)
'reset' : reset wealth index to 1 after missing spell
Returns
-------
pd.DataFrame
"""
df = df.sort_values([group_col, "date"]).copy()
results = []
for name, group in df.groupby(group_col):
cumret = 1.0
cumrets = []
for _, row in group.iterrows():
ret = row[ret_col]
if pd.notna(ret):
cumret = cumret * (1 + ret)
else:
if handle_missing == "propagate":
cumret = np.nan
elif handle_missing == "reset":
cumret = 1.0
# 'carry' does nothing (cumret unchanged)
cumrets.append(cumret)
group = group.copy()
group["wealth_iter"] = cumrets
group["cumret_iter"] = group["wealth_iter"] - 1
results.append(group)
return pd.concat(results, ignore_index=True)
Note
The iterative method is the slowest of the four approaches because it cannot leverage NumPy’s vectorized operations. For large datasets, prefer Method 1 or 2 unless the conditional logic in Method 3 is essential. On a dataset with 1 million observations, Method 1 runs in approximately 0.1 seconds versus 10+ seconds for Method 3.
7.6.1 Comparison of Missing Value Treatments
To illustrate how the three missing-value strategies differ, consider a hypothetical stock with one missing return in the middle of its history:
example = pd.DataFrame({
"symbol": [1]*6,
"date": pd.date_range("2024-01-31", periods=6, freq="ME"),
"ret_total": [0.05, 0.03, np.nan, 0.04, -0.02, 0.06]
})
carry = compute_cumret_iterative(example, handle_missing="carry")
propagate = compute_cumret_iterative(
example, handle_missing="propagate"
)
reset = compute_cumret_iterative(example, handle_missing="reset")
comparison = pd.DataFrame({
"Date": example["date"].dt.strftime("%Y-%m"),
"Return": example["ret_total"],
"Carry": carry["cumret_iter"].round(6),
"Propagate": propagate["cumret_iter"].round(6),
"Reset": reset["cumret_iter"].round(6)
})
comparison| Date | Return | Carry | Propagate | Reset | |
|---|---|---|---|---|---|
| 0 | 2024-01 | 0.05 | 0.050000 | 0.0500 | 0.050000 |
| 1 | 2024-02 | 0.03 | 0.081500 | 0.0815 | 0.081500 |
| 2 | 2024-03 | NaN | 0.081500 | NaN | 0.000000 |
| 3 | 2024-04 | 0.04 | 0.124760 | NaN | 0.040000 |
| 4 | 2024-05 | -0.02 | 0.102265 | NaN | 0.019200 |
| 5 | 2024-06 | 0.06 | 0.168401 | NaN | 0.080352 |
7.7 Method 4: Rolling Compound Returns
For many empirical applications, including momentum strategies, performance evaluation, and risk estimation, we need compound returns over rolling windows of fixed length. This section implements efficient rolling compounding using pandas.
7.7.1 Rolling Window via Log Returns
The most efficient approach combines the log-sum-exp method with rolling sums:
def rolling_compound_return(df, ret_col="ret_total",
group_col="symbol",
windows=[3, 6, 9, 12]):
"""Compute rolling compound returns over specified windows.
Parameters
----------
df : pd.DataFrame
Must be sorted by [group_col, 'date'] with no gaps.
ret_col : str
group_col : str
windows : list of int
Rolling window lengths (in periods).
Returns
-------
pd.DataFrame with new columns ret_{k} for each window k.
"""
df = df.sort_values([group_col, "date"]).copy()
df["log_ret"] = np.log(1 + df[ret_col])
for k in windows:
rolling_logsum = (
df.groupby(group_col)["log_ret"]
.transform(
lambda x: x.rolling(
window=k, min_periods=k
).sum()
)
)
df[f"ret_{k}"] = np.exp(rolling_logsum) - 1
df.drop(columns=["log_ret"], inplace=True)
return dfWe apply this to our full sample to compute 3-, 6-, 9-, and 12-month trailing compound returns:
stock_rolling = rolling_compound_return(
prices_monthly,
windows=[3, 6, 9, 12]
)Let us also compute the same rolling returns for the market index, which serves as a benchmark for excess return calculations:
# Compute market rolling returns
market_monthly = (
prices_monthly[["date", "mkt_total"]]
.drop_duplicates()
.sort_values("date")
.copy()
)
market_monthly["log_mkt"] = np.log(1 + market_monthly["mkt_total"])
for k in [3, 6, 9, 12]:
market_monthly[f"mkt_{k}"] = (
np.exp(
market_monthly["log_mkt"]
.rolling(window=k, min_periods=k)
.sum()
) - 1
)
market_monthly.drop(columns=["log_mkt"], inplace=True)
# Merge market rolling returns back
stock_rolling = stock_rolling.merge(
market_monthly[
["date"] + [f"mkt_{k}" for k in [3, 6, 9, 12]]
],
on="date",
how="left"
)Figure 35.4 displays the distribution of 12-month rolling compound returns over time.
rolling_stats = (
stock_rolling
.dropna(subset=["ret_12"])
.groupby("date")["ret_12"]
.agg(["median", lambda x: x.quantile(0.25),
lambda x: x.quantile(0.75)])
.reset_index()
)
rolling_stats.columns = ["date", "median", "p25", "p75"]
plot_rolling = (
ggplot(rolling_stats, aes(x="date")) +
geom_ribbon(aes(ymin="p25", ymax="p75"),
alpha=0.3, fill="#2166ac") +
geom_line(aes(y="median"), color="#2166ac", size=0.7) +
geom_hline(yintercept=0, linetype="dashed") +
labs(x="", y="12-month compound return") +
scale_y_continuous(labels=percent_format()) +
theme_minimal() +
theme(figure_size=(10, 5))
)
plot_rolling.draw()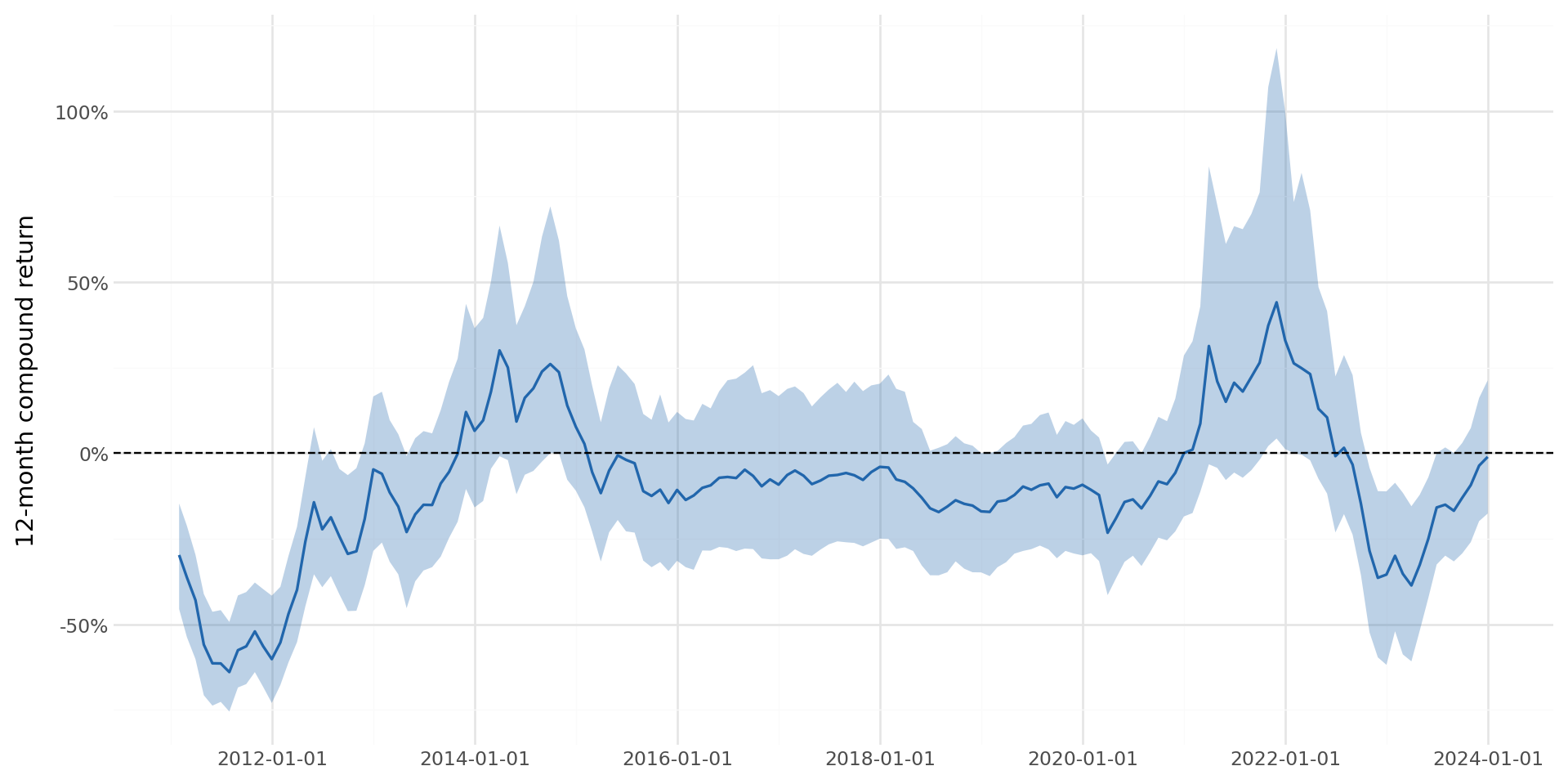
7.7.2 Verifying Rolling Returns
It is prudent to verify rolling compound returns against a direct calculation. We select one stock and recompute its 12-month return manually:
test_stock = long_history_stocks[0]
test_data = (
stock_rolling[stock_rolling["symbol"] == test_stock]
.sort_values("date")
.tail(15)
.copy()
)
# Direct computation
test_data["direct_ret_12"] = (
test_data["ret_total"]
.transform(
lambda x: x.add(1).rolling(
12, min_periods=12
).apply(np.prod, raw=True) - 1
)
)
verify = (
test_data[["date", "ret_12", "direct_ret_12"]]
.dropna()
.tail(5)
.copy()
)
verify["difference"] = (
verify["ret_12"] - verify["direct_ret_12"]
).abs()
verify.round(8)/tmp/ipykernel_2229780/922053246.py:28: UserWarning: obj.round has no effect with datetime, timedelta, or period dtypes. Use obj.dt.round(...) instead.| date | ret_12 | direct_ret_12 | difference | |
|---|---|---|---|---|
| 386 | 2023-09-30 | -0.152407 | -0.152407 | 0.0 |
| 387 | 2023-10-31 | -0.208836 | -0.208836 | 0.0 |
| 388 | 2023-11-30 | -0.199018 | -0.199018 | 0.0 |
| 389 | 2023-12-31 | -0.233698 | -0.233698 | 0.0 |
7.8 Delisting Returns and Survivorship Bias
A critical practical concern when computing compound returns is the treatment of securities that are removed from an exchange. Delisting occurs for various reasons: mergers and acquisitions, bankruptcy, failure to meet listing requirements, voluntary withdrawal, or transfer to another exchange. If delisting returns are not incorporated, the resulting compound returns suffer from survivorship bias: they overstate performance because the worst outcomes (bankruptcies, forced delistings) are excluded (Shumway 1997).
7.8.1 The Vietnamese Context
In Vietnam, securities can be removed from their exchange listing for several reasons as specified by the SSC and exchange regulations:
- Mandatory delisting: when a firm has accumulated losses exceeding its charter capital, fails to meet financial reporting obligations for three consecutive years, or has its business license revoked.
- Voluntary delisting: when a firm’s shareholders vote to withdraw from the exchange.
- Transfer: when a firm moves from UPCoM to HOSE/HNX (upgrade) or from HOSE/HNX to UPCoM (downgrade). These transfers are not true delistings in the economic sense but require careful handling in return calculations.
Unlike more developed markets where detailed delisting return data is systematically compiled, Vietnamese market data may not always provide an explicit delisting return. When a stock is delisted for cause (e.g., bankruptcy), the last traded price may significantly overstate the security’s recovery value. Researchers should be aware of this limitation and consider imputing delisting returns based on the delisting reason, following the methodology of Shumway (1997).
7.8.2 Incorporating Delisting Returns
When a security is delisted, a final “delisting return” captures the value change between the last regular trading day and the realization of value after delisting. This return must be combined with the regular return in the delisting month:
\[ R_t^{\text{adj}} = (1 + R_t)(1 + R_t^{\text{delist}}) - 1, \tag{7.12}\]
where \(R_t\) is the regular return and \(R_t^{\text{delist}}\) is the delisting return. If the regular return is missing (the stock ceased trading before month end), we use the delisting return alone.
def adjust_for_delisting(df, ret_col="ret_total",
dlret_col="dlret"):
"""Adjust returns for delisting events.
Parameters
----------
df : pd.DataFrame
Must contain `ret_col` and `dlret_col`.
Returns
-------
pd.DataFrame with adjusted return column 'ret_adj'.
"""
df = df.copy()
df["ret_adj"] = df[ret_col]
# Case 1: Both regular and delisting returns available
mask_both = df[ret_col].notna() & df[dlret_col].notna()
df.loc[mask_both, "ret_adj"] = (
(1 + df.loc[mask_both, ret_col]) *
(1 + df.loc[mask_both, dlret_col]) - 1
)
# Case 2: Only delisting return available
mask_dlret_only = (
df[ret_col].isna() & df[dlret_col].notna()
)
df.loc[mask_dlret_only, "ret_adj"] = (
df.loc[mask_dlret_only, dlret_col]
)
return df7.8.3 Impact of Delisting Adjustment
The magnitude of the delisting bias depends on the frequency and severity of delisting events. Shumway (1997) showed that, in developed markets, ignoring delisting returns introduces an upward bias of approximately 1% per year in equal-weighted portfolio returns. The bias is larger for small-cap stocks and value stocks, which are more prone to financial distress. In Vietnam, where smaller firms on HNX and UPCoM face tighter liquidity constraints and higher default risk, the bias may be even more pronounced. In emerging market delistings, mandatory delistings often involve firms with severe financial distress where residual equity value is near zero, implying delisting returns close to \(-100\%\) in the worst cases.
7.9 Rolling Volatility Estimation
Stock return volatility is a key input for risk management, option pricing, and many empirical asset pricing models. A common approach is to estimate rolling standard deviations of returns over a trailing window.
7.9.1 24-Month Rolling Volatility
Following Ben-David, Franzoni, and Moussawi (2012), we compute the total stock return volatility as the rolling standard deviation of monthly returns over a 24-month window:
\[ \hat{\sigma}_{i,t}^{24} = \sqrt{\frac{1}{23}\sum_{j=0}^{23}(R_{i,t-j} - \bar{R}_{i,t}^{24})^2}, \tag{7.13}\]
where \(\bar{R}_{i,t}^{24} = \frac{1}{24}\sum_{j=0}^{23} R_{i,t-j}\) is the trailing 24-month mean return.
def rolling_volatility(df, ret_col="ret_total",
group_col="symbol",
window=24):
"""Compute rolling return volatility.
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
window : int
Rolling window length in periods.
Returns
-------
pd.DataFrame with 'vol_{window}' column (annualized).
"""
df = df.sort_values([group_col, "date"]).copy()
df[f"vol_{window}"] = (
df.groupby(group_col)[ret_col]
.transform(
lambda x: x.rolling(
window=window, min_periods=window
).std()
)
)
# Annualize (monthly to annual)
df[f"vol_{window}_ann"] = df[f"vol_{window}"] * np.sqrt(12)
return dfstock_vol = rolling_volatility(stock_rolling)Figure 7.3 shows the cross-sectional distribution of annualized 24-month volatility over time.
vol_stats = (
stock_vol
.dropna(subset=["vol_24_ann"])
.groupby("date")["vol_24_ann"]
.agg(["median", lambda x: x.quantile(0.25),
lambda x: x.quantile(0.75)])
.reset_index()
)
vol_stats.columns = ["date", "median", "p25", "p75"]
plot_vol = (
ggplot(vol_stats, aes(x="date")) +
geom_ribbon(aes(ymin="p25", ymax="p75"),
alpha=0.3, fill="#b2182b") +
geom_line(aes(y="median"), color="#b2182b", size=0.7) +
labs(x="", y="Annualized 24-month volatility") +
scale_y_continuous(labels=percent_format()) +
theme_minimal() +
theme(figure_size=(10, 5))
)
plot_vol.draw()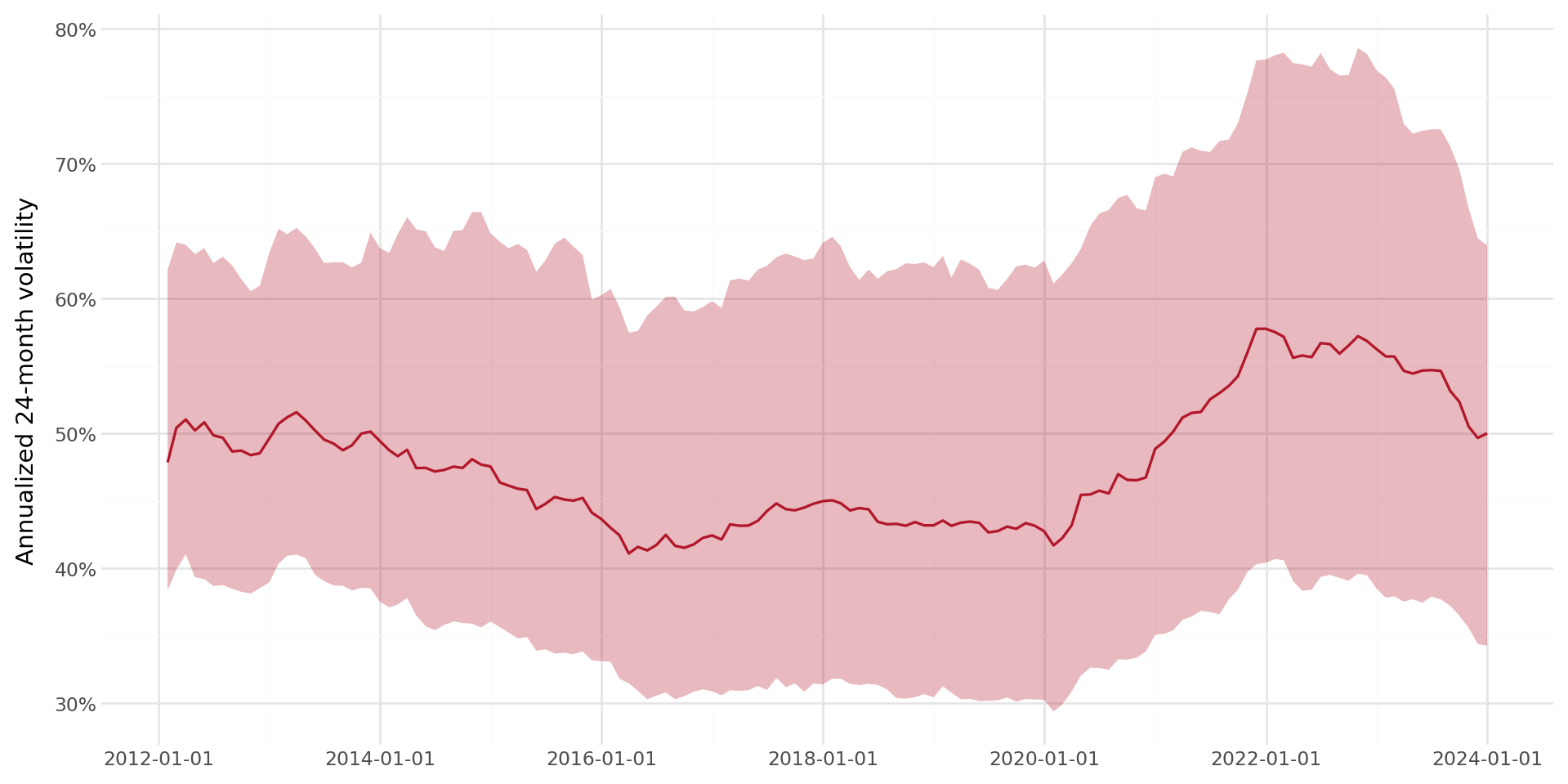
7.9.2 Volatility and Compound Returns: The Variance Drain
As noted in Equation 7.7, the geometric mean return falls below the arithmetic mean by approximately \(\sigma^2/2\). This “variance drain” or “volatility drag” means that two portfolios with the same arithmetic mean return but different volatilities will have different compound returns: the lower-volatility portfolio will compound to greater terminal wealth.
This effect is quantitatively important in Vietnam. A stock with an arithmetic mean monthly return of 1.5% and a monthly standard deviation of 10% suffers a volatility drag of approximately \(0.10^2/2 = 0.5\%\) per month, or roughly 6% per year. This is consistent with the observation that Vietnamese investors face substantial erosion of compound wealth from the high idiosyncratic volatility of individual stocks. We can verify this empirically by sorting stocks into volatility quintiles and comparing compound returns:
annual_data = compound_return_by_period(
prices_monthly, period="year"
)
annual_data = annual_data[annual_data["n_obs"] >= 10].copy()
vol_annual = (
prices_monthly
.groupby(["symbol", prices_monthly["date"].dt.year])[
"ret_total"
]
.agg(["std", "mean", "count"])
.reset_index()
)
vol_annual.columns = ["symbol", "period", "monthly_std",
"monthly_mean", "n_months"]
vol_annual = vol_annual[vol_annual["n_months"] >= 10].copy()
vol_annual["ann_vol"] = vol_annual["monthly_std"] * np.sqrt(12)
vol_annual["arith_mean_ann"] = vol_annual["monthly_mean"] * 12
vol_analysis = annual_data.merge(
vol_annual, on=["symbol", "period"]
)
vol_analysis["vol_quintile"] = (
vol_analysis.groupby("period")["ann_vol"]
.transform(
lambda x: pd.qcut(
x, 5, labels=[1, 2, 3, 4, 5], duplicates="drop"
)
)
)
vol_summary = (
vol_analysis
.groupby("vol_quintile")
.agg(
arithmetic_mean=("arith_mean_ann", "mean"),
geometric_mean=("cumret", "mean"),
avg_volatility=("ann_vol", "mean"),
n_stockyears=("cumret", "count")
)
.round(4)
.reset_index()
)
vol_summary| vol_quintile | arithmetic_mean | geometric_mean | avg_volatility | n_stockyears | |
|---|---|---|---|---|---|
| 0 | 1 | -0.0908 | -0.0763 | 0.1887 | 2708 |
| 1 | 2 | -0.0754 | -0.0610 | 0.3312 | 2700 |
| 2 | 3 | -0.0388 | -0.0169 | 0.4493 | 2701 |
| 3 | 4 | 0.0404 | 0.0494 | 0.6005 | 2700 |
| 4 | 5 | 0.4411 | 0.3389 | 1.0288 | 2705 |
7.10 Compound Returns Around Fiscal Year Ends
A widely used approach in accounting and finance research aligns compound returns to firm-specific fiscal period end dates. This is essential for computing buy-and-hold abnormal returns (BHARs) for event studies, post-earnings-announcement drift, and other studies where the event date varies by firm.
In Vietnam, the majority of listed firms follow a calendar fiscal year (January–December), as required by the Law on Accounting unless the Ministry of Finance grants an exemption. However, firms in certain industries (e.g., agriculture, tourism) may use non-standard fiscal years ending in March, June, or September.
7.10.1 Aligning Returns to Fiscal Periods
The key challenge is that fiscal year ends differ across firms. We need to compute compound returns over windows anchored at these firm-specific dates.
def compound_returns_around_event(
returns_df, events_df,
id_col="symbol", date_col="date",
event_date_col="datadate", ret_col="ret_total",
pre_windows=[3, 6, 9, 12],
post_windows=[3, 6]
):
"""Compute compound returns in windows around firm-specific
event dates.
Parameters
----------
returns_df : pd.DataFrame
Monthly returns with [id_col, date_col, ret_col].
events_df : pd.DataFrame
Event dates with [id_col, event_date_col].
pre_windows : list of int
Trailing window lengths (months before event).
post_windows : list of int
Forward window lengths (months after event).
Returns
-------
pd.DataFrame with compound returns for each window.
"""
returns_df = returns_df.sort_values(
[id_col, date_col]
).copy()
events_df = events_df.copy()
# Align event dates to month ends
events_df["event_month"] = (
pd.to_datetime(events_df[event_date_col])
+ pd.offsets.MonthEnd(0)
)
results = []
for _, event in events_df.iterrows():
sid = event[id_col]
edate = event["event_month"]
sec_rets = returns_df[
returns_df[id_col] == sid
].copy()
sec_rets = sec_rets.set_index(date_col)[ret_col]
row = {id_col: sid,
event_date_col: event[event_date_col]}
# Pre-event compound returns
for k in pre_windows:
start = edate - pd.DateOffset(months=k-1)
start = (start - pd.offsets.MonthEnd(0)
+ pd.offsets.MonthEnd(0))
window_rets = sec_rets[
(sec_rets.index >= start)
& (sec_rets.index <= edate)
]
if len(window_rets) >= k * 0.8:
cumret = (
np.exp(np.log(1 + window_rets).sum()) - 1
)
else:
cumret = np.nan
row[f"ret_pre_{k}"] = cumret
# Post-event compound returns
for k in post_windows:
start = edate + pd.DateOffset(months=1)
end = (edate + pd.DateOffset(months=k)
+ pd.offsets.MonthEnd(0))
window_rets = sec_rets[
(sec_rets.index >= start)
& (sec_rets.index <= end)
]
if len(window_rets) >= k * 0.8:
cumret = (
np.exp(np.log(1 + window_rets).sum()) - 1
)
else:
cumret = np.nan
row[f"ret_post_{k}"] = cumret
results.append(row)
return pd.DataFrame(results)7.10.2 Buy-and-Hold Abnormal Returns versus Cumulative Abnormal Returns
For event studies and performance evaluation, we often want the excess compound return, which is the stock’s compound return minus a benchmark’s compound return over the same window. The buy-and-hold abnormal return (BHAR) is defined as
\[ \text{BHAR}_{i,t}(k) = \prod_{j=1}^{k}(1 + R_{i,t+j}) - \prod_{j=1}^{k}(1 + R_{b,t+j}), \tag{7.14}\]
where \(R_{b,t}\) is the benchmark return (market index, size-matched portfolio, etc.). This differs from the cumulative abnormal return (CAR), which sums simple abnormal returns:
\[ \text{CAR}_{i,t}(k) = \sum_{j=1}^{k}(R_{i,t+j} - R_{b,t+j}). \tag{7.15}\]
The BHAR better captures the actual investor experience because it reflects the compounding of returns, whereas the CAR implicitly assumes daily rebalancing to maintain equal dollar positions in the stock and benchmark (Barber and Lyon 1997). The distinction is particularly important in Vietnam, where individual stock returns can be highly volatile and the compounding effect is therefore magnified. Lyon, Barber, and Tsai (1999) provide further analysis of the statistical properties of BHARs and recommend bootstrapped critical values for inference.
def compute_bhar(stock_returns, benchmark_returns):
"""Compute buy-and-hold abnormal return.
Parameters
----------
stock_returns : array-like
Sequence of stock returns.
benchmark_returns : array-like
Sequence of benchmark returns (same length).
Returns
-------
float : BHAR
"""
stock_cumret = (
np.prod(1 + np.array(stock_returns)) - 1
)
bench_cumret = (
np.prod(1 + np.array(benchmark_returns)) - 1
)
return stock_cumret - bench_cumret7.11 Book Value of Equity
Many empirical applications that use compound returns also require firm-level accounting variables. A commonly used variable is the book value of equity, computed following Daniel and Titman (1997):
\[ \text{BE} = \text{SE} + \text{DT} + \text{ITC} - \text{PS}, \tag{7.16}\]
where SE is stockholders’ equity, DT is deferred taxes, ITC is investment tax credit, and PS is the preferred stock value. For preferred stock, the hierarchy is: redemption value if available, then liquidating value, then carrying value.
In Vietnam, the accounting standards (Vietnamese Accounting Standards, VAS, and increasingly IFRS adoption) provide a somewhat different chart of accounts. Stockholders’ equity is reported on the balance sheet as Vốn chủ sở hữu, which includes contributed capital (Vốn góp của chủ sở hữu), share premium (Thặng dư vốn cổ phần), treasury stock adjustments, retained earnings (Lợi nhuận sau thuế chưa phân phối), and other reserves. Deferred tax assets and liabilities are reported separately. Preferred stock is rare among Vietnamese listed firms (most issue only common shares), but when present, its book value should be subtracted from total equity.
def compute_book_equity(df):
"""Compute book value of equity for Vietnamese firms.
Parameters
----------
df : pd.DataFrame
Must contain at minimum: equity (stockholders' equity),
deferred_tax (deferred tax liabilities, net),
pref_stock (preferred stock, if applicable).
Returns
-------
pd.DataFrame with 'be' column.
"""
df = df.copy()
df["pref"] = df.get(
"pref_stock", pd.Series(0, index=df.index)
)
df["dt"] = df.get(
"deferred_tax", pd.Series(0, index=df.index)
)
df["be"] = (
df["equity"].fillna(0)
+ df["dt"].fillna(0)
- df["pref"].fillna(0)
)
# Set non-positive book equity to NaN
df.loc[df["be"] <= 0, "be"] = np.nan
return df7.12 Maximum Drawdown
The maximum drawdown is a key risk metric that complements volatility. While volatility measures the dispersion of returns symmetrically, the maximum drawdown captures the worst cumulative loss an investor could experience: a measure that aligns more closely with how investors psychologically experience risk (Kahneman and Tversky 2013).
def compute_max_drawdown(df, ret_col="ret_total",
group_col="symbol"):
"""Compute maximum drawdown for each security.
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
Returns
-------
pd.DataFrame with 'max_drawdown' and running drawdown.
"""
df = df.sort_values([group_col, "date"]).copy()
df["gross_ret"] = 1 + df[ret_col]
df["wealth"] = (
df.groupby(group_col)["gross_ret"].cumprod()
)
df["peak"] = df.groupby(group_col)["wealth"].cummax()
df["drawdown"] = (
(df["wealth"] - df["peak"]) / df["peak"]
)
max_dd = (
df.groupby(group_col)["drawdown"]
.min()
.reset_index(name="max_drawdown")
)
df = df.merge(max_dd, on=group_col)
df.drop(columns=["gross_ret"], inplace=True)
return dfFigure 35.7 illustrates the drawdown profile for a selected stock.
dd_data = compute_max_drawdown(
prices_monthly[
prices_monthly["symbol"] == long_history_stocks[0]
]
)
mdd = dd_data["max_drawdown"].iloc[0]
plot_dd = (
ggplot(dd_data, aes(x="date", y="drawdown")) +
geom_area(fill="#b2182b", alpha=0.4) +
geom_line(color="#b2182b", size=0.5) +
geom_hline(yintercept=mdd, linetype="dashed") +
labs(x="", y="Drawdown from peak") +
scale_y_continuous(labels=percent_format()) +
theme_minimal() +
theme(figure_size=(10, 4))
)
plot_dd.draw()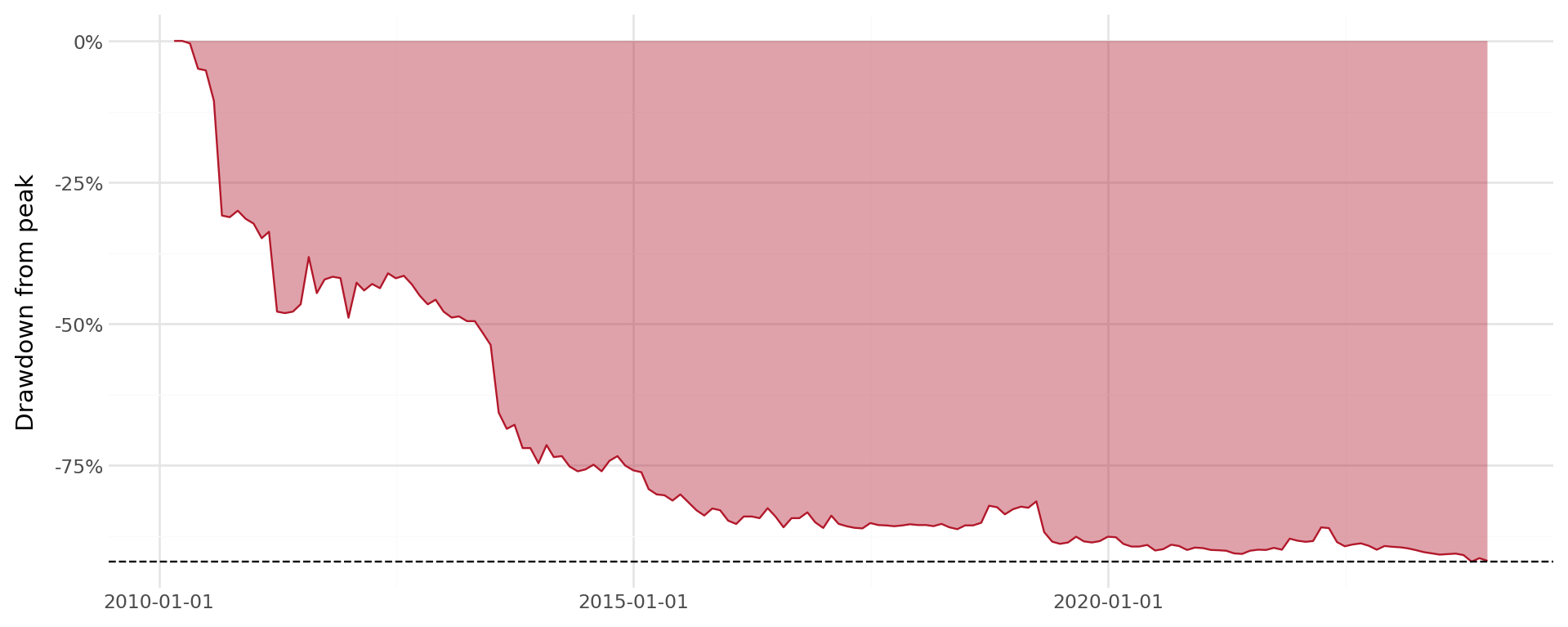
7.13 Putting It All Together: A Comprehensive Pipeline
We now combine all the methods into a single pipeline that produces a research-ready dataset with rolling compound returns, market returns, volatility, and drawdown measures.
def build_compound_return_dataset(
stock_df, windows=[3, 6, 9, 12], vol_window=24
):
"""Build comprehensive compound return dataset.
Parameters
----------
stock_df : pd.DataFrame
Monthly stock return data with columns:
symbol, date, ret_total, mkt_total.
windows : list of int
Rolling compound return windows.
vol_window : int
Rolling volatility window.
Returns
-------
pd.DataFrame
"""
df = stock_df.sort_values(["symbol", "date"]).copy()
# Step 1: Log returns
df["log_ret"] = np.log(1 + df["ret_total"])
df["log_mkt"] = np.log(1 + df["mkt_total"])
# Step 2: Rolling compound returns (stock and market)
for k in windows:
df[f"ret_{k}"] = np.exp(
df.groupby("symbol")["log_ret"]
.transform(
lambda x: x.rolling(k, min_periods=k).sum()
)
) - 1
df[f"mkt_{k}"] = np.exp(
df["log_mkt"]
.rolling(k, min_periods=k)
.sum()
) - 1
# Excess compound return (BHAR vs market)
df[f"exret_{k}"] = df[f"ret_{k}"] - df[f"mkt_{k}"]
# Step 3: Cumulative return (full history)
df["wealth"] = (
df.groupby("symbol")["log_ret"]
.cumsum()
.apply(np.exp)
)
df["cumret"] = df["wealth"] - 1
# Step 4: Rolling volatility
df[f"vol_{vol_window}"] = (
df.groupby("symbol")["ret_total"]
.transform(
lambda x: x.rolling(
vol_window, min_periods=vol_window
).std()
)
) * np.sqrt(12) # annualize
# Step 5: Drawdown
df["peak"] = df.groupby("symbol")["wealth"].cummax()
df["drawdown"] = (df["wealth"] - df["peak"]) / df["peak"]
# Clean up
df.drop(
columns=["log_ret", "log_mkt", "peak"], inplace=True
)
return df# Build the full dataset
compound_dataset = build_compound_return_dataset(prices_monthly)Table 7.7 provides summary statistics for the key variables in our compound return dataset.
summary_cols = ["ret_total", "ret_3", "ret_6", "ret_12",
"exret_3", "exret_12", "vol_24", "drawdown"]
available_cols = [c for c in summary_cols
if c in compound_dataset.columns]
summary = (
compound_dataset[available_cols]
.describe(percentiles=[0.05, 0.25, 0.50, 0.75, 0.95])
.T
.round(4)
)
summary| count | mean | std | min | 5% | 25% | 50% | 75% | 95% | max | |
|---|---|---|---|---|---|---|---|---|---|---|
| ret_total | 165499.0 | 0.0042 | 0.1862 | -0.9900 | -0.2381 | -0.0703 | 0.0000 | 0.0553 | 0.2773 | 12.7500 |
| ret_3 | 162586.0 | 0.0094 | 0.3393 | -0.9999 | -0.3889 | -0.1436 | -0.0126 | 0.0987 | 0.5000 | 27.2911 |
| ret_6 | 158227.0 | 0.0171 | 0.5053 | -0.9999 | -0.5095 | -0.2196 | -0.0400 | 0.1404 | 0.7320 | 35.7136 |
| ret_12 | 149520.0 | 0.0375 | 0.8136 | -0.9999 | -0.6522 | -0.3191 | -0.0877 | 0.1807 | 1.0767 | 47.9515 |
| exret_3 | 153637.0 | 0.0385 | 0.3343 | -1.1691 | -0.3420 | -0.1163 | 0.0067 | 0.1378 | 0.4992 | 27.3041 |
| exret_12 | 140571.0 | 0.1401 | 0.8031 | -1.5858 | -0.5388 | -0.2003 | 0.0281 | 0.2880 | 1.1119 | 48.0488 |
| vol_24 | 132233.0 | 0.5493 | 0.3488 | 0.0000 | 0.2070 | 0.3445 | 0.4827 | 0.6737 | 1.0739 | 9.1792 |
| drawdown | 165499.0 | -0.5927 | 0.2975 | -1.0000 | -0.9631 | -0.8501 | -0.6616 | -0.3725 | 0.0000 | 0.0000 |
7.14 Cross-Sectional Distribution of Compound Returns
To understand how compound returns vary across securities, we examine the cross-sectional distribution at different horizons.
horizon_data = pd.DataFrame()
for k in [3, 6, 12]:
col = f"ret_{k}"
temp = compound_dataset[[col]].dropna().copy()
temp.columns = ["compound_return"]
temp["horizon"] = f"{k} months"
lo, hi = temp["compound_return"].quantile([0.01, 0.99])
temp = temp[
(temp["compound_return"] >= lo)
& (temp["compound_return"] <= hi)
]
horizon_data = pd.concat([horizon_data, temp])
plot_horizons = (
ggplot(horizon_data,
aes(x="compound_return", fill="horizon")) +
geom_density(alpha=0.4) +
geom_vline(xintercept=0, linetype="dashed") +
labs(x="Compound return", y="Density", fill="Horizon") +
scale_x_continuous(labels=percent_format()) +
theme_minimal() +
theme(legend_position="bottom",
figure_size=(10, 5))
)
plot_horizons.draw()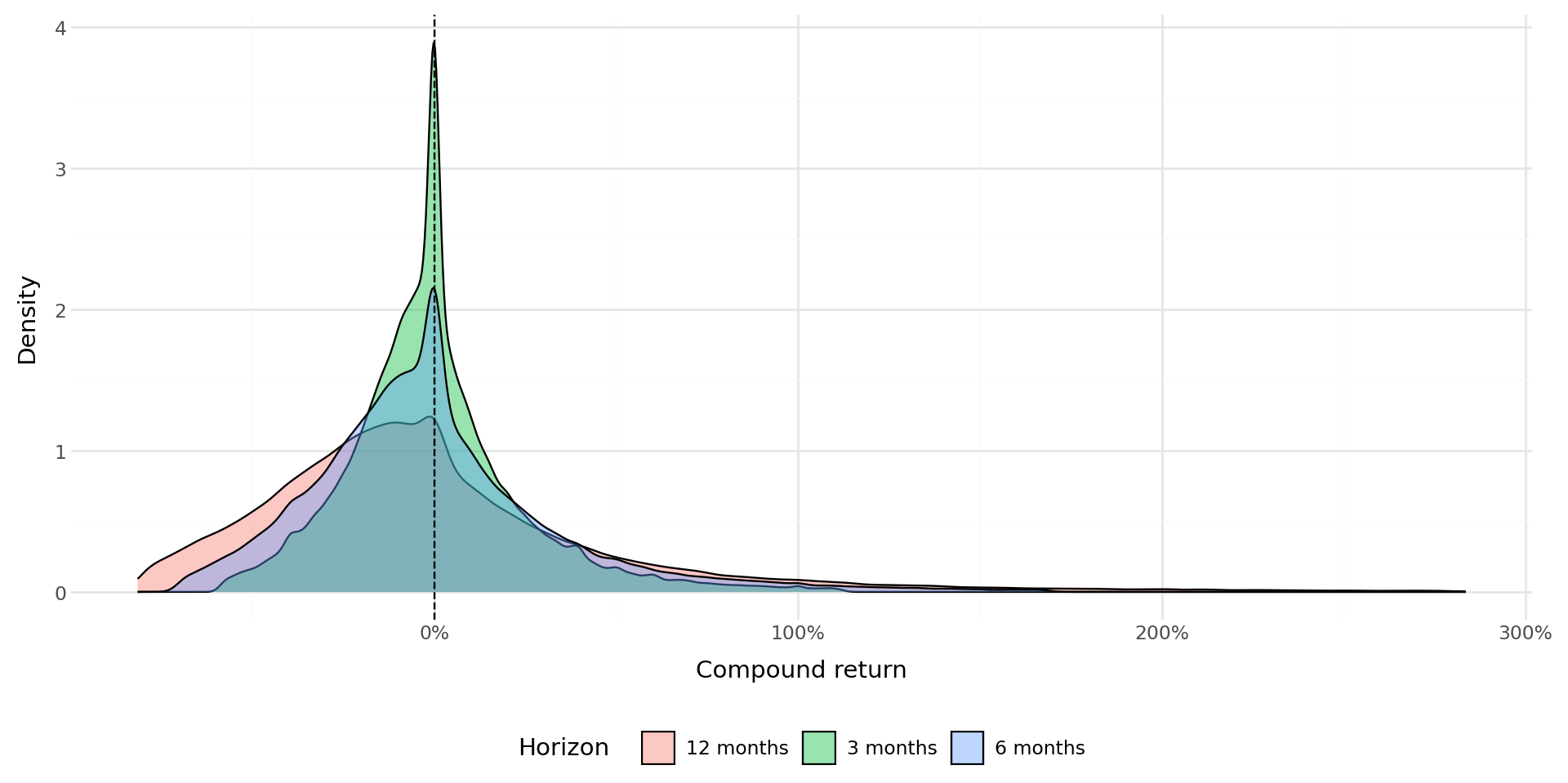
7.15 Vietnam-Specific Considerations
7.15.1 Price Limits and Their Effect on Compounding
Vietnam’s stock exchanges impose daily price limits that cap the maximum price change from the reference price. As of the latest regulations:
- HOSE: \(\pm 7\%\)
- HNX: \(\pm 10\%\)
- UPCoM: \(\pm 15\%\)
These limits truncate the daily return distribution and can create sequences of limit-hit days when large information events occur. For compound return computation, this means that the adjustment to new information may be spread over multiple days rather than occurring instantaneously. When computing monthly compound returns from daily data, this is handled correctly because the compound return accumulates the full adjustment regardless of how many days it takes.
However, price limits can introduce bias in short-horizon return computations. If a large positive event occurs and the stock hits the limit-up ceiling for several consecutive days, the 1-day or 1-week compound return will understate the true information content of the event (Kim, Liu, and Yang 2013). For event study applications, researchers should verify that the event window is long enough to accommodate the price-limit-induced delay in price adjustment.
7.15.2 Foreign Ownership Limits
Vietnam imposes foreign ownership limits (FOL) on listed companies, typically capped at 49% for most industries and lower (30% or less) for certain restricted sectors such as banking and telecommunications. When a stock reaches its FOL, foreign investors can only purchase shares from other foreign sellers, creating a parallel premium market for foreign-board shares. This does not directly affect the computation of compound returns (which use official traded prices), but researchers studying cross-border portfolio returns should be aware that the effective price paid by foreign investors may differ from the board price (Vo 2017).
7.15.3 The VN-Index and Market Benchmarks
For benchmark compound returns, Vietnam’s primary indices are:
- VN-Index: The capitalization-weighted index of all HOSE-listed stocks.
- VN30: The 30 largest and most liquid stocks on HOSE, reviewed semi-annually.
- HNX-Index: The capitalization-weighted index of HNX-listed stocks.
The VN-Index is the most widely used benchmark and is the default market return in our dataset.
7.16 Performance Considerations
When working with large datasets, computational efficiency matters. Table 7.8 compares the execution time of our four compounding methods on a standardized dataset.
import time
np.random.seed(42)
n_stocks = 100
n_months = 100
test_df = pd.DataFrame({
"symbol": np.repeat(range(n_stocks), n_months),
"date": np.tile(
pd.date_range("2015-01-31", periods=n_months,
freq="ME"),
n_stocks
),
"ret_total": np.random.normal(
0.01, 0.08, n_stocks * n_months
)
})
methods = {}
t0 = time.time()
_ = compute_cumret_cumprod(test_df)
methods["Cumulative Product"] = time.time() - t0
t0 = time.time()
_ = compute_cumret_logsum(test_df)
methods["Log-Sum-Exp"] = time.time() - t0
t0 = time.time()
_ = compute_cumret_iterative(test_df)
methods["Iterative (carry)"] = time.time() - t0
t0 = time.time()
_ = rolling_compound_return(test_df, windows=[12])
methods["Rolling (12-month)"] = time.time() - t0
perf_df = pd.DataFrame({
"Method": methods.keys(),
"Time (seconds)": [f"{v:.4f}" for v in methods.values()],
"Relative Speed": [
f"{v/min(methods.values()):.1f}x"
for v in methods.values()
]
})
perf_df| Method | Time (seconds) | Relative Speed | |
|---|---|---|---|
| 0 | Cumulative Product | 0.0039 | 1.0x |
| 1 | Log-Sum-Exp | 0.0043 | 1.1x |
| 2 | Iterative (carry) | 0.5225 | 132.7x |
| 3 | Rolling (12-month) | 0.0230 | 5.8x |
7.17 Common Pitfalls and Best Practices
Several subtle issues can lead to incorrect compound return calculations. We summarize the most important ones:
Gaps in the time series. If a security has months with no observations (not even a missing return flag), rolling window calculations based on positional indexing will produce incorrect results. The rolling window will span the wrong calendar period. Always ensure that the time series is complete, fill gaps with explicit missing values before computing rolling statistics. This is particularly relevant in Vietnam, where trading suspensions can create gaps.
Survivorship bias. As discussed in the delisting returns section, excluding securities that cease trading biases compound returns upward. Always incorporate delisting returns when available. When delisting returns are unavailable (as is sometimes the case in Vietnamese data), consider using imputed values based on the delisting reason.
Look-ahead bias. When aligning compound returns to fiscal year ends for cross-sectional analysis, be careful not to use returns from before the fiscal year end to predict post-announcement returns. Vietnamese firms are required to publish audited annual financial statements within 90 days of the fiscal year end, so a buffer of at least 3 months is advisable when constructing forward-looking compound returns.
Numerical overflow and underflow. For very long compounding horizons or extreme returns, the cumulative product can overflow (inf) or underflow (0). The log-sum-exp approach is more robust to such numerical issues because it operates in log space where the range is compressed.
Annualization of partial periods. When computing annualized returns from partial-period data (e.g., 7 months of data annualized to 12), the annualization formula \((1+R)^{12/k} - 1\) assumes that the observed return rate will persist. This assumption is stronger for short partial periods and can produce misleading results. Report the actual compound return and the number of periods alongside any annualized figures.
Exchange transfers. In Vietnam, stocks sometimes transfer between UPCoM, HNX, and HOSE. These transfers may involve temporary trading halts and can cause apparent gaps in the return series. When computing compound returns that span an exchange transfer, ensure that the return series is continuous across the transfer date.