import pandas as pd
import numpy as np
import sqlite3
import matplotlib.pyplot as plt
from plotnine import *
from mizani.formatters import percent_format, comma_format, date_format
from itertools import product
from datetime import datetime, timedelta7 Lợi nhuận kép
Trong chương này, chúng tôi trình bày về lợi nhuận kép. Cho dù là xây dựng danh mục đầu tư mua và nắm giữ, đánh giá hiệu suất quỹ, tính toán chỉ số tài sản tích lũy hay ước tính các thước đo rủi ro dài hạn, khả năng tính toán chính xác lợi nhuận kép trong các khoảng thời gian bất kỳ là điều không thể thiếu. Chúng tôi bắt đầu với nền tảng toán học: sự khác biệt giữa lợi nhuận đơn giản và lợi nhuận logarit, mối quan hệ giữa trung bình cộng và trung bình hình học, và các đặc tính của lợi nhuận kép liên tục. Trên đường đi, chúng tôi đề cập đến các vấn đề phức tạp thực tiễn phát sinh trong dữ liệu chứng khoán thực tế, chẳng hạn như tạm ngừng giao dịch, cơ chế giới hạn giá, lợi nhuận trong một phần kỳ và các sự kiện hủy niêm yết, và chỉ ra cách xử lý chúng trong bối cảnh Việt Nam.
Chương này tiếp tục trình bày về lợi suất kép luân chuyển trong các kỳ hạn tiêu chuẩn (3, 6, 9 và 12 tháng), lợi suất kép phù hợp với thời điểm kết thúc kỳ kế toán, lợi suất tích lũy hướng tới tương lai cho các nghiên cứu sự kiện và ước tính biến động luân chuyển.
7.1 Lợi nhuận cơ bản so với lợi nhuận logarit
Trước khi thảo luận về lãi kép, chúng ta cần phân biệt giữa hai quy ước lợi nhuận cơ bản được sử dụng trong tài chính.
7.1.1 Lợi nhuận cơ bản (số học)
Lợi nhuận gộp cơ bản trên một tài sản từ kỳ \(t-1\) đến \(t\) được định nghĩa như sau:
\[ 1 + R_t = \frac{P_t + D_t}{P_{t-1}}, \tag{7.1}\]
Trong đó, \(P_t\) biểu thị giá vào cuối kỳ \(t\) và \(D_t\) biểu thị bất kỳ khoản phân phối tiền mặt nào (cổ tức, lãi suất) được trả trong kỳ \(t\). Lợi nhuận ròng đơn giản chính là \(R_t\). Khi chúng ta nói về “lợi nhuận” mà không có sự giải thích rõ ràng, chúng ta thường muốn nói đến lợi nhuận ròng đơn giản.
Đặc tính quan trọng của lợi nhuận đơn giản là lãi kép nhiều kỳ có tính chất nhân:
\[ 1 + R_t(k) = \prod_{j=0}^{k-1} (1 + R_{t-j}) = (1 + R_t)(1 + R_{t-1}) \cdots (1 + R_{t-k+1}), \tag{7.2}\]
trong đó \(R_t(k)\) là lợi nhuận kép kỳ \(k\) kết thúc tại thời điểm \(t\). Cấu trúc nhân này là nền tảng của tất cả các phương pháp tính lãi kép được thảo luận trong chương này.
7.1.2 Lợi nhuận kép liên tục (Log)
Lợi tức kép liên tục, hay lợi tức logarit, được định nghĩa là
\[ r_t = \ln(1 + R_t) = \ln\!\left(\frac{P_t + D_t}{P_{t-1}}\right). \tag{7.3}\]
Ưu điểm trung tâm của lợi nhuận log để cộng gộp là lãi kép nhiều kỳ trở thành cộng :
\[ r_t(k) = \ln(1 + R_t(k)) = \sum_{j=0}^{k-1} r_{t-j} = r_t + r_{t-1} + \cdots + r_{t-k+1}. \tag{7.4}\]
Tính chất cộng này xuất phát trực tiếp từ đẳng thức logarit \(\ln(ab) = \ln(a) + \ln(b)\). Nó thuận tiện về mặt tính toán vì phép cộng ổn định hơn về mặt số học so với phép nhân lặp lại, và vì nhiều thủ tục thống kê (trung bình, phương sai, hồi quy) hoạt động một cách tự nhiên trên các đại lượng có tính chất cộng.
Để thu được lợi nhuận kép đơn giản từ tổng lợi nhuận logarit, chúng ta áp dụng hàm mũ:
\[ R_t(k) = \exp\!\left(\sum_{j=0}^{k-1} r_{t-j}\right) - 1. \tag{7.5}\]
7.1.3 Khi nào thì chúng bắt đầu khác biệt?
Đối với lợi nhuận nhỏ, phép xấp xỉ \(r_t \approx R_t\) đúng ở bậc nhất (thông qua khai triển Taylor \(\ln(1+x) \approx x\) với \(|x| \ll 1\)). Tuy nhiên, đối với lợi nhuận lớn, thường thấy ở các thị trường mới nổi, cổ phiếu vốn hóa nhỏ hoặc trong thời kỳ khủng hoảng, hai giá trị này có thể khác biệt đáng kể. Hãy xem xét một cổ phiếu có giá tăng gấp đôi (\(R_t = 1,0\)): lợi nhuận logarit là \(r_t = \ln(2) \approx 0,693\), chênh lệch 31%. Ngược lại, đối với một cổ phiếu mất một nửa giá trị (\(R_t = -0,5\)): lợi nhuận logarit là \(r_t = \ln(0,5) \approx -0,693\), lớn hơn 39%.
Sự khác biệt này đặc biệt đáng chú ý ở Việt Nam, nơi giới hạn giá hàng ngày là ±7% trên HOSE, ±10% trên HNX và ±15% trên UPCoM có thể tạo ra chuỗi ngày tăng hoặc giảm kịch trần. Trong một tuần liên tiếp tăng kịch trần trên HOSE, lợi nhuận đơn giản là \((1,07)^5 - 1 = 40,3%\) trong khi lợi nhuận logarit là \(5 \times \ln(1,07) = 33,8%\), đây là một khoảng cách đáng kể.
Table 7.1 minh họa sự khác biệt này trên một dải các giá trị trên nhiều mức độ lợi nhuận khác nhau.
simple_returns = [-0.50, -0.30, -0.15, -0.10, -0.07, -0.05, -0.01,
0.00, 0.01, 0.05, 0.07, 0.10, 0.15, 0.30, 0.50, 1.00]
comparison_df = pd.DataFrame({
"Simple Return": [f"{r:.2%}" for r in simple_returns],
"Log Return": [f"{np.log(1+r):.4f}" for r in simple_returns],
"Difference": [f"{np.log(1+r) - r:.4f}" for r in simple_returns],
"Relative Error (%)": [
f"{((np.log(1+r) - r) / abs(r) * 100):.2f}" if r != 0 else "—"
for r in simple_returns
]
})
comparison_df| Simple Return | Log Return | Difference | Relative Error (%) | |
|---|---|---|---|---|
| 0 | -50.00% | -0.6931 | -0.1931 | -38.63 |
| 1 | -30.00% | -0.3567 | -0.0567 | -18.89 |
| 2 | -15.00% | -0.1625 | -0.0125 | -8.35 |
| 3 | -10.00% | -0.1054 | -0.0054 | -5.36 |
| 4 | -7.00% | -0.0726 | -0.0026 | -3.67 |
| 5 | -5.00% | -0.0513 | -0.0013 | -2.59 |
| 6 | -1.00% | -0.0101 | -0.0001 | -0.50 |
| 7 | 0.00% | 0.0000 | 0.0000 | — |
| 8 | 1.00% | 0.0100 | -0.0000 | -0.50 |
| 9 | 5.00% | 0.0488 | -0.0012 | -2.42 |
| 10 | 7.00% | 0.0677 | -0.0023 | -3.34 |
| 11 | 10.00% | 0.0953 | -0.0047 | -4.69 |
| 12 | 15.00% | 0.1398 | -0.0102 | -6.83 |
| 13 | 30.00% | 0.2624 | -0.0376 | -12.55 |
| 14 | 50.00% | 0.4055 | -0.0945 | -18.91 |
| 15 | 100.00% | 0.6931 | -0.3069 | -30.69 |
Điểm mấu chốt: Lợi nhuận theo logarit rất thuận tiện cho việc tính lãi kép (tổng hợp cộng), nhưng lợi nhuận danh mục đầu tư được tổng hợp theo chiều ngang trong không gian lợi nhuận đơn giản. Trên thực tế, chúng ta thường chuyển đổi sang lợi nhuận theo logarit để tính lãi kép theo thời gian, sau đó chuyển đổi lại thành lợi nhuận đơn giản để báo cáo.
7.2 Cơ sở toán học của tính lãi kép
7.2.1 Lợi tức trung bình hình học
Lợi tức trung bình hình học trong \(T\) kỳ là
\[ \bar{R}_g = \left(\prod_{t=1}^{T} (1 + R_t)\right)^{1/T} - 1, \tag{7.6}\]
Giá trị này thể hiện tỷ suất lợi nhuận không đổi mỗi kỳ, tạo ra cùng một mức tài sản cuối kỳ như chuỗi lợi nhuận thực tế. Nó luôn nhỏ hơn hoặc bằng trung bình cộng \(\bar{R}_a = \frac{1}{T}\sum_{t=1}^{T} R_t\), và chỉ bằng nhau khi tất cả các tỷ suất lợi nhuận đều giống nhau. Mối quan hệ giữa hai giá trị này xấp xỉ như sau:
\[ \bar{R}_g \approx \bar{R}_a - \frac{\sigma^2}{2}, \tag{7.7}\]
trong đó \(\sigma^2\) là phương sai của lợi nhuận. Sự xấp xỉ này, đôi khi được gọi là “lực cản biến động”, có ý nghĩa quan trọng: các tài sản có độ biến động cao có khoảng cách lớn hơn giữa các phương tiện số học và hình học của chúng, có nghĩa là sự tăng trưởng kép thực tế của chúng đánh giá thấp những gì một mức trung bình ngây thơ sẽ gợi ý. Trong một thị trường như Việt Nam, nơi biến động cổ phiếu riêng lẻ thường gấp hai đến ba lần so với chứng khoán các thị trường phát triển, lực cản biến động có thể là đáng kể.
7.2.2 Chỉ số tài sản và sụt giảm
Với khoản đầu tư ban đầu là \(W_0\), tài sản tại thời điểm \(T\) là
\[ W_T = W_0 \prod_{t=1}^{T} (1 + R_t). \tag{7.8}\]
Lợi nhuận tích lũy (ròng) đơn giản là \(W_T / W_0 - 1\). Mức giảm tối đa, một thước đo rủi ro được sử dụng rộng rãi, được định nghĩa là
\[ \text{MDD} = \max_{0 \le s \le t \le T} \left(\frac{W_s - W_t}{W_s}\right), \tag{7.9}\]
đo lường mức giảm từ đỉnh đến đáy lớn nhất trong chỉ số tài sản. Chúng tôi sẽ tính toán số lượng này cùng với lợi nhuận kép bên dưới. Sự sụt giảm đặc biệt có nhiều thông tin ở các thị trường mới nổi trải qua những đợt điều chỉnh mạnh, như đã xảy ra trong cuộc khủng hoảng tài chính toàn cầu năm 2008 khi VN-Index giảm khoảng 66% so với mức đỉnh năm 2007.
7.2.3 Tính toán hàng năm
Đối với lợi suất kép trong \(k\) kỳ \(R_t(k)\), trong đó mỗi kỳ có độ dài \(\Delta\) (ví dụ, \(\Delta = 1/12\) cho dữ liệu hàng tháng), lợi suất hàng năm là
\[ R_{\text{ann}} = (1 + R_t(k))^{1/(k\Delta)} - 1. \tag{7.10}\]
Tương tự, đối với độ biến động được ước tính từ lợi nhuận \(k\) kỳ với độ dài kỳ \(\Delta\):
\[ \sigma_{\text{ann}} = \sigma / \sqrt{\Delta}, \tag{7.11}\]
Vì vậy, độ biến động hàng tháng được tính theo năm bằng cách nhân với \(\sqrt{12}\) và độ biến động hàng ngày được tính bằng khoảng \(\sqrt{252}\) (giả sử có 252 ngày giao dịch mỗi năm). Riêng đối với Việt Nam, Sở Giao dịch Chứng khoán Hà Nội (HOSE) thường có khoảng 245-250 ngày giao dịch mỗi năm sau khi tính cả các ngày lễ của Việt Nam, con số này đủ gần để quy ước \(\sqrt{252}\) trở thành tiêu chuẩn.
7.3 Chuẩn bị dữ liệu
Chúng ta bắt đầu bằng cách tải dữ liệu lợi nhuận cổ phiếu hàng tháng từ cơ sở dữ liệu SQLite. Như đã chuẩn bị trong các chương trước, cơ sở dữ liệu này chứa lợi nhuận hàng tháng được lấy từ DataCore.vn cho tất cả các chứng khoán niêm yết trên Sở Giao dịch Chứng khoán Thành phố Hồ Chí Minh (HOSE), Sở Giao dịch Chứng khoán Hà Nội (HNX) và Thị trường Công ty Đại chúng Chưa niêm yết (UPCoM). Lợi nhuận được điều chỉnh cho việc chia tách cổ phiếu, phát hành cổ phiếu thưởng và chào bán quyền mua cổ phiếu, và bao gồm cả cổ tức tiền mặt được tái đầu tư.
tidy_finance = sqlite3.connect(database="data/tidy_finance_python.sqlite")
prices_monthly = pd.read_sql_query(
sql="""
SELECT symbol, date, ret_excess, ret, mktcap, mktcap_lag, risk_free
FROM prices_monthly
""",
con=tidy_finance,
parse_dates=["date"]
).dropna()
factors_ff3_monthly = pd.read_sql_query(
sql="SELECT date, mkt_excess FROM factors_ff3_monthly",
con=tidy_finance,
parse_dates=["date"]
)
prices_monthly = prices_monthly.merge(
factors_ff3_monthly,
on="date",
how="left"
)
prices_monthly["ret_total"] = prices_monthly["ret"]
prices_monthly["mkt_total"] = (
prices_monthly["mkt_excess"] + prices_monthly["risk_free"]
)Chúng ta hãy cùng xem xét mẫu:
print(f"Sample period: {prices_monthly['date'].min()} to "
f"{prices_monthly['date'].max()}")
print(f"Number of stocks: {prices_monthly['symbol'].nunique():,}")
print(f"Total observations: {len(prices_monthly):,}")
# print(f"Exchanges: {prices_monthly['exchange'].unique()}")Sample period: 2010-02-28 00:00:00 to 2023-12-31 00:00:00
Number of stocks: 1,457
Total observations: 165,499Table 7.2 cung cấp số liệu thống kê tóm tắt về lợi nhuận thô hàng tháng, được chia nhỏ theo sàn giao dịch. Sự khác biệt giữa các sàn giao dịch phản ánh quy mô và độ dốc thanh khoản: HOSE liệt kê các công ty lớn nhất và có tính thanh khoản cao nhất, HNX bao gồm các công ty vốn hóa trung bình và UPCoM lưu trữ các chứng khoán nhỏ hơn và được giao dịch mỏng hơn.
sample_stats = (
prices_monthly
.groupby("exchange")["ret_total"]
.describe(percentiles=[0.05, 0.25, 0.50, 0.75, 0.95])
.round(4)
)
sample_stats7.4 Phương pháp 1: Tích lũy thông qua GroupBy
Cách tiếp cận trực tiếp nhất đối với lợi nhuận kép sử dụng tính chất nhân trong Equation 7.2. Đối với mỗi chứng khoán, chúng ta tính tích lũy của lợi nhuận gộp \((1 + R_t)\) trong khoảng thời gian mong muốn.
def compute_cumret_cumprod(df, ret_col="ret_total",
group_col="symbol"):
"""Compute cumulative returns using cumulative product.
Parameters
----------
df : pd.DataFrame
Must contain `group_col`, 'date', and `ret_col`.
ret_col : str
Column name for period returns.
group_col : str
Column name for grouping (e.g., security identifier).
Returns
-------
pd.DataFrame
Original DataFrame augmented with 'cumret' and 'wealth_index'.
"""
df = df.sort_values([group_col, "date"]).copy()
df["gross_ret"] = 1 + df[ret_col]
df["wealth_index"] = (
df.groupby(group_col)["gross_ret"]
.cumprod()
)
df["cumret"] = df["wealth_index"] - 1
df.drop(columns=["gross_ret"], inplace=True)
return dfChúng ta hãy áp dụng điều này cho toàn bộ mẫu và xem xét các chỉ số tài sản thu được đối với một vài cổ phiếu được chọn:
stock_cumret = compute_cumret_cumprod(prices_monthly)
# Select stocks with long histories for illustration
stock_counts = (
stock_cumret.groupby("symbol")["date"]
.count()
.reset_index(name="n_obs")
)
long_history_stocks = (
stock_counts.nlargest(5, "n_obs")["symbol"].tolist()
)
sample_wealth = stock_cumret[
stock_cumret["symbol"].isin(long_history_stocks)
]Figure 7.1 vẽ các chỉ số tài sản (giá trị 1 đồng đầu tư) cho năm chứng khoán này trong toàn bộ thời gian lấy mẫu.
plot_wealth = (
ggplot(sample_wealth, aes(x="date", y="wealth_index",
color="factor(symbol)")) +
geom_line(size=0.6) +
labs(
x="", y="Wealth index (1 VND invested)",
color="Stock"
) +
theme_minimal() +
theme(legend_position="bottom",
figure_size=(10, 5))
)
plot_wealth.draw()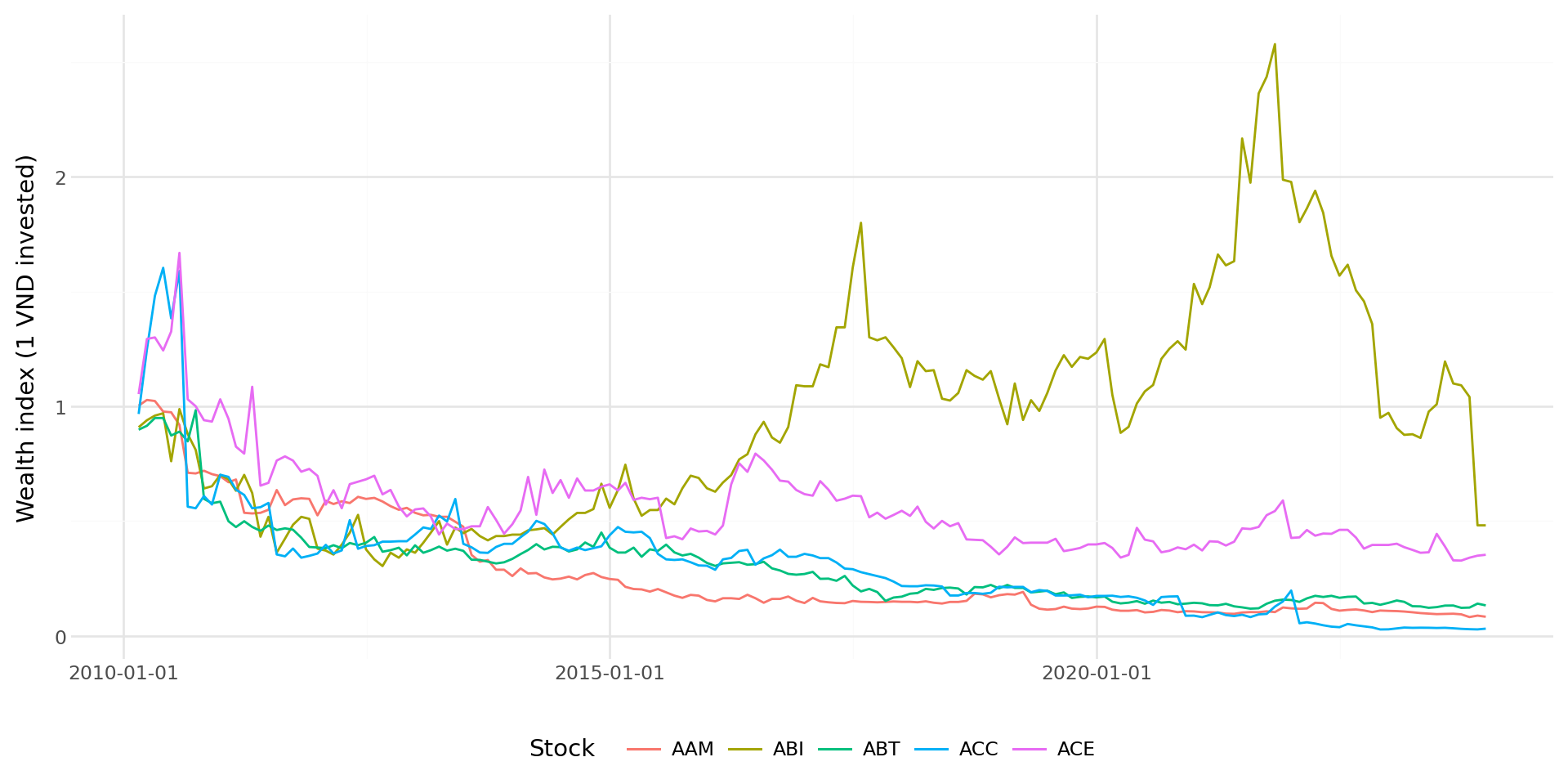
7.4.1 Xử lý các khoản trả về bị thiếu
Phương pháp tích lũy giá trị lan truyền các giá trị thiếu: nếu bất kỳ \(R_t\) nào là NaN, toàn bộ tích lũy giá trị từ điểm đó trở đi sẽ trở thành NaN. Điều này mang tính thận trọng vì nó giả định rằng việc thiếu lợi nhuận sẽ khiến chỉ số tài sản tiếp theo không xác định. Trong nhiều ứng dụng, đây là hành vi mong muốn vì việc thiếu lợi nhuận có thể cho thấy lỗi dữ liệu hoặc khoảng thời gian cổ phiếu không được giao dịch.
Tuy nhiên, tại thị trường Việt Nam, việc thiếu lợi nhuận có thể phát sinh do tạm ngừng giao dịch kéo dài. Ủy ban Chứng khoán Nhà nước (SSC) và các sở giao dịch có thể tạm ngừng giao dịch cổ phiếu vì nhiều lý do pháp lý khác nhau, chẳng hạn như chậm trễ báo cáo tài chính, thông báo tái cấu trúc doanh nghiệp đang chờ xử lý hoặc nghi ngờ thao túng thị trường. Việc tạm ngừng này có thể kéo dài nhiều ngày, nhiều tuần, thậm chí nhiều tháng. Trong thời gian tạm ngừng như vậy, giá trị cổ phiếu không thay đổi (giá giao dịch cuối cùng vẫn được dùng làm giá tham chiếu), vì vậy việc coi lợi nhuận thiếu là bằng không (tức là không có sự thay đổi giá) có thể phù hợp hơn là sử dụng giá trị NaN.
def compute_cumret_skipna(df, ret_col="ret_total",
group_col="symbol"):
"""Compute cumulative returns, treating missing returns as zero."""
df = df.sort_values([group_col, "date"]).copy()
df["gross_ret"] = 1 + df[ret_col].fillna(0)
df["wealth_index"] = (
df.groupby(group_col)["gross_ret"]
.cumprod()
)
df["cumret"] = df["wealth_index"] - 1
df.drop(columns=["gross_ret"], inplace=True)
return df
Warning
Việc coi các giá trị lợi nhuận bị thiếu là bằng không là một giả định có thể phù hợp hoặc không. Nếu lợi nhuận bị thiếu do cổ phiếu bị tạm ngừng giao dịch, thì việc gán giá trị bằng không có thể hợp lý. Nếu lợi nhuận bị thiếu do lỗi dữ liệu hoặc do cổ phiếu thực sự không được giao dịch (ví dụ: đang chờ niêm yết lại sau một sự kiện của công ty), việc gán giá trị bằng không có thể gây ra sai lệch. Luôn luôn điều tra lý do thiếu giá trị trước khi quyết định phương pháp xử lý.
7.5 Phương pháp 2: Phương pháp tiếp cận Log-Sum-Exp
Phương thức log-sum-exp khai thác thuộc tính cộng của log return (Equation 7.4). Cách tiếp cận này đặc biệt hữu ích khi tính toán lợi nhuận kép qua các cửa sổ cố định (ví dụ: lợi nhuận hàng năm từ dữ liệu hàng tháng) vì tính tổng vừa hiệu quả về mặt tính toán vừa ổn định về mặt số.
def compute_cumret_logsum(df, ret_col="ret_total",
group_col="symbol",
date_col="date"):
"""Compute cumulative returns using the log-sum-exp approach.
Steps:
1. Transform to log returns: r_t = ln(1 + R_t)
2. Cumulative sum of log returns within each group
3. Exponentiate to recover simple cumulative return
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
date_col : str
Returns
-------
pd.DataFrame
"""
df = df.sort_values([group_col, date_col]).copy()
df["log_ret"] = np.log(1 + df[ret_col])
df["cum_log_ret"] = (
df.groupby(group_col)["log_ret"].cumsum()
)
df["wealth_index_log"] = np.exp(df["cum_log_ret"])
df["cumret_log"] = df["wealth_index_log"] - 1
df.drop(columns=["log_ret", "cum_log_ret"], inplace=True)
return dfChúng ta hãy kiểm tra xem hai phương pháp này có cho ra kết quả giống hệt nhau hay không (đến độ chính xác dấu phẩy động):
stock_both = compute_cumret_cumprod(prices_monthly)
stock_both = compute_cumret_logsum(stock_both)
# Compare on non-missing observations
mask = (stock_both["cumret"].notna()
& stock_both["cumret_log"].notna())
max_diff = (stock_both.loc[mask, "cumret"] -
stock_both.loc[mask, "cumret_log"]).abs().max()
print(f"Maximum absolute difference between methods: {max_diff:.2e}")Maximum absolute difference between methods: 1.78e-14Sự khác biệt là ở cấp độ epsilon của máy (\(\approx 10^{-15}\)), xác nhận sự tương đương về số.
7.5.1 Lợi nhuận kép cụ thể theo khoảng thời gian
Một nhiệm vụ phổ biến là tính toán lợi nhuận kép trong các khoảng thời gian dương lịch (tháng, quý, năm). Cách tiếp cận log-sum-exp tự nhiên cho phép tổng hợp nhóm:
def compound_return_by_period(df, ret_col="ret_total",
group_col="symbol",
period="year"):
"""Compute compound returns within calendar periods.
Parameters
----------
df : pd.DataFrame
Must contain 'date' and `ret_col`.
period : str
One of 'year', 'quarter', 'month'.
Returns
-------
pd.DataFrame with compound returns per group-period.
"""
df = df.copy()
df["log_ret"] = np.log(1 + df[ret_col])
if period == "year":
df["period"] = df["date"].dt.year
elif period == "quarter":
df["period"] = df["date"].dt.to_period("Q")
elif period == "month":
df["period"] = df["date"].dt.to_period("M")
result = (
df.groupby([group_col, "period"])
.agg(
cumret=(
"log_ret",
lambda x: np.exp(x.sum()) - 1
),
n_obs=("log_ret", "count"),
n_miss=(ret_col, lambda x: x.isna().sum()),
start_date=("date", "min"),
end_date=("date", "max")
)
.reset_index()
)
return resultTable 7.3 hiển thị tỷ suất lợi nhuận kép hàng năm cho một tập hợp con các chứng khoán.
annual_returns = compound_return_by_period(
prices_monthly[
prices_monthly["symbol"].isin(long_history_stocks)
],
period="year"
)
recent_annual = (
annual_returns
.sort_values(["symbol", "period"])
.groupby("symbol")
.tail(5)
.round(4)
)
recent_annual.head(20)/tmp/ipykernel_260635/2619242959.py:13: UserWarning: obj.round has no effect with datetime, timedelta, or period dtypes. Use obj.dt.round(...) instead.| symbol | period | cumret | n_obs | n_miss | start_date | end_date | |
|---|---|---|---|---|---|---|---|
| 9 | AAM | 2019 | -0.2810 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 10 | AAM | 2020 | -0.1622 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 11 | AAM | 2021 | 0.1250 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 12 | AAM | 2022 | -0.0913 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 13 | AAM | 2023 | -0.2337 | 12 | 0 | 2023-01-31 | 2023-12-31 |
| 23 | ABI | 2019 | 0.1946 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 24 | ABI | 2020 | 0.2418 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 25 | ABI | 2021 | 0.2896 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 26 | ABI | 2022 | -0.5085 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 27 | ABI | 2023 | -0.5042 | 12 | 0 | 2023-01-31 | 2023-12-31 |
| 37 | ABT | 2019 | -0.1893 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 38 | ABT | 2020 | -0.1400 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 39 | ABT | 2021 | 0.0842 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 40 | ABT | 2022 | -0.0789 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 41 | ABT | 2023 | -0.0768 | 12 | 0 | 2023-01-31 | 2023-12-31 |
| 51 | ACC | 2019 | -0.1875 | 12 | 0 | 2019-01-31 | 2019-12-31 |
| 52 | ACC | 2020 | -0.4923 | 12 | 0 | 2020-01-31 | 2020-12-31 |
| 53 | ACC | 2021 | 1.2339 | 12 | 0 | 2021-01-31 | 2021-12-31 |
| 54 | ACC | 2022 | -0.8538 | 12 | 0 | 2022-01-31 | 2022-12-31 |
| 55 | ACC | 2023 | 0.1027 | 12 | 0 | 2023-01-31 | 2023-12-31 |
Important
Khi số lượng quan sát không bị thiếu (n_obs) nhỏ hơn 12 đối với lợi nhuận hàng năm, lợi nhuận kép chỉ thể hiện một phần của năm. Điều này thường xảy ra trong năm đầu tiên và năm cuối cùng khi một chứng khoán được niêm yết trên HOSE, HNX hoặc UPCoM, hoặc khi một cổ phiếu được chuyển đổi giữa các sàn giao dịch (ví dụ: từ UPCoM sang HOSE sau khi đáp ứng các yêu cầu niêm yết). Người dùng nên quyết định giữ lại hay loại bỏ các quan sát không đầy đủ như vậy tùy thuộc vào thiết kế nghiên cứu của họ.
7.6 Phương pháp 3: Kết hợp lặp đi lặp lại với logic giữ nguyên
Trong một số ứng dụng, chúng ta cần kiểm soát chi tiết cách các giá trị thiếu, sự kiện loại bỏ khỏi danh sách hoặc các điều kiện đặc biệt khác ảnh hưởng đến quá trình tính lãi kép. Phương pháp lặp xử lý từng quan sát một cách tuần tự, chuyển tiếp lợi nhuận tích lũy và áp dụng logic điều kiện ở mỗi bước.
def compute_cumret_iterative(df, ret_col="ret_total",
group_col="symbol",
handle_missing="carry"):
"""Compute cumulative returns iteratively with flexible
missing value handling.
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
handle_missing : str
'carry' : treat missing as zero return (carry forward)
'propagate' : propagate NaN (conservative)
'reset' : reset wealth index to 1 after missing spell
Returns
-------
pd.DataFrame
"""
df = df.sort_values([group_col, "date"]).copy()
results = []
for name, group in df.groupby(group_col):
cumret = 1.0
cumrets = []
for _, row in group.iterrows():
ret = row[ret_col]
if pd.notna(ret):
cumret = cumret * (1 + ret)
else:
if handle_missing == "propagate":
cumret = np.nan
elif handle_missing == "reset":
cumret = 1.0
# 'carry' does nothing (cumret unchanged)
cumrets.append(cumret)
group = group.copy()
group["wealth_iter"] = cumrets
group["cumret_iter"] = group["wealth_iter"] - 1
results.append(group)
return pd.concat(results, ignore_index=True)
Note
Phương pháp lặp là phương pháp chậm nhất trong bốn phương pháp vì nó không thể tận dụng các phép toán vector hóa của NumPy. Đối với các tập dữ liệu lớn, nên ưu tiên Phương pháp 1 hoặc 2 trừ khi logic điều kiện trong Phương pháp 3 là cần thiết. Trên tập dữ liệu có 1 triệu quan sát, Phương pháp 1 chạy trong khoảng 0,1 giây so với hơn 10 giây đối với Phương pháp 3.
7.6.1 So sánh các phương pháp xử lý giá trị thiếu
Để minh họa sự khác biệt giữa ba chiến lược xử lý giá trị thiếu, hãy xem xét một cổ phiếu giả định có một lợi nhuận bị thiếu ở giữa lịch sử giao dịch của nó:
example = pd.DataFrame({
"symbol": [1]*6,
"date": pd.date_range("2024-01-31", periods=6, freq="ME"),
"ret_total": [0.05, 0.03, np.nan, 0.04, -0.02, 0.06]
})
carry = compute_cumret_iterative(example, handle_missing="carry")
propagate = compute_cumret_iterative(
example, handle_missing="propagate"
)
reset = compute_cumret_iterative(example, handle_missing="reset")
comparison = pd.DataFrame({
"Date": example["date"].dt.strftime("%Y-%m"),
"Return": example["ret_total"],
"Carry": carry["cumret_iter"].round(6),
"Propagate": propagate["cumret_iter"].round(6),
"Reset": reset["cumret_iter"].round(6)
})
comparison| Date | Return | Carry | Propagate | Reset | |
|---|---|---|---|---|---|
| 0 | 2024-01 | 0.05 | 0.050000 | 0.0500 | 0.050000 |
| 1 | 2024-02 | 0.03 | 0.081500 | 0.0815 | 0.081500 |
| 2 | 2024-03 | NaN | 0.081500 | NaN | 0.000000 |
| 3 | 2024-04 | 0.04 | 0.124760 | NaN | 0.040000 |
| 4 | 2024-05 | -0.02 | 0.102265 | NaN | 0.019200 |
| 5 | 2024-06 | 0.06 | 0.168401 | NaN | 0.080352 |
7.7 Phương pháp 4: Lợi nhuận kép tích lũy
Đối với nhiều ứng dụng thực nghiệm, bao gồm các chiến lược dựa trên động lượng, đánh giá hiệu suất và ước tính rủi ro, chúng ta cần lợi nhuận kép trên các cửa sổ trượt có độ dài cố định. Phần này trình bày cách tính lợi nhuận kép trượt hiệu quả bằng thư viện pandas.
7.7.1 Cửa sổ trượt thông qua lợi nhuận từ nhật ký
Phương pháp hiệu quả nhất là kết hợp phương pháp logarit tổng lũy thừa với tổng tích lũy:
def rolling_compound_return(df, ret_col="ret_total",
group_col="symbol",
windows=[3, 6, 9, 12]):
"""Compute rolling compound returns over specified windows.
Parameters
----------
df : pd.DataFrame
Must be sorted by [group_col, 'date'] with no gaps.
ret_col : str
group_col : str
windows : list of int
Rolling window lengths (in periods).
Returns
-------
pd.DataFrame with new columns ret_{k} for each window k.
"""
df = df.sort_values([group_col, "date"]).copy()
df["log_ret"] = np.log(1 + df[ret_col])
for k in windows:
rolling_logsum = (
df.groupby(group_col)["log_ret"]
.transform(
lambda x: x.rolling(
window=k, min_periods=k
).sum()
)
)
df[f"ret_{k}"] = np.exp(rolling_logsum) - 1
df.drop(columns=["log_ret"], inplace=True)
return dfChúng ta áp dụng điều này cho toàn bộ mẫu dữ liệu để tính toán tỷ suất lợi nhuận kép trong 3, 6, 9 và 12 tháng:
stock_rolling = rolling_compound_return(
prices_monthly,
windows=[3, 6, 9, 12]
)Chúng ta cũng hãy tính toán lợi nhuận luân chuyển tương tự cho chỉ số thị trường, vốn được dùng làm chuẩn mực để tính toán lợi nhuận vượt trội:
# Compute market rolling returns
market_monthly = (
prices_monthly[["date", "mkt_total"]]
.drop_duplicates()
.sort_values("date")
.copy()
)
market_monthly["log_mkt"] = np.log(1 + market_monthly["mkt_total"])
for k in [3, 6, 9, 12]:
market_monthly[f"mkt_{k}"] = (
np.exp(
market_monthly["log_mkt"]
.rolling(window=k, min_periods=k)
.sum()
) - 1
)
market_monthly.drop(columns=["log_mkt"], inplace=True)
# Merge market rolling returns back
stock_rolling = stock_rolling.merge(
market_monthly[
["date"] + [f"mkt_{k}" for k in [3, 6, 9, 12]]
],
on="date",
how="left"
)Figure 35.4 hiển thị sự phân bố lợi nhuận kép tích lũy trong 12 tháng theo thời gian.
rolling_stats = (
stock_rolling
.dropna(subset=["ret_12"])
.groupby("date")["ret_12"]
.agg(["median", lambda x: x.quantile(0.25),
lambda x: x.quantile(0.75)])
.reset_index()
)
rolling_stats.columns = ["date", "median", "p25", "p75"]
plot_rolling = (
ggplot(rolling_stats, aes(x="date")) +
geom_ribbon(aes(ymin="p25", ymax="p75"),
alpha=0.3, fill="#2166ac") +
geom_line(aes(y="median"), color="#2166ac", size=0.7) +
geom_hline(yintercept=0, linetype="dashed") +
labs(x="", y="12-month compound return") +
scale_y_continuous(labels=percent_format()) +
theme_minimal() +
theme(figure_size=(10, 5))
)
plot_rolling.draw()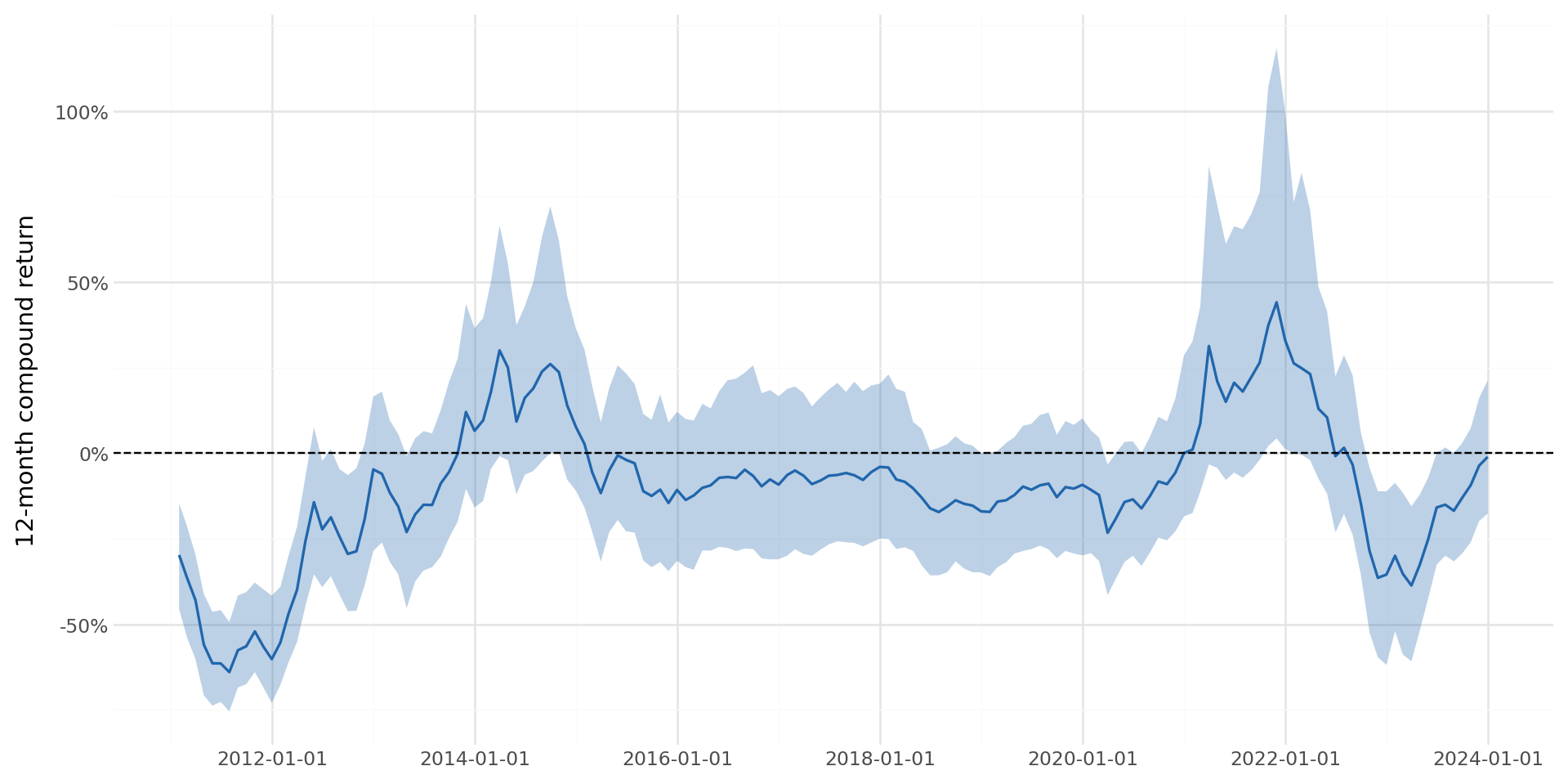
7.7.2 Xác minh lợi nhuận luân chuyển
Nên kiểm tra lại tỷ suất lợi nhuận kép so với phép tính trực tiếp. Chúng tôi chọn một cổ phiếu và tính toán lại tỷ suất lợi nhuận 12 tháng của nó theo cách thủ công:
test_stock = long_history_stocks[0]
test_data = (
stock_rolling[stock_rolling["symbol"] == test_stock]
.sort_values("date")
.tail(15)
.copy()
)
# Direct computation
test_data["direct_ret_12"] = (
test_data["ret_total"]
.transform(
lambda x: x.add(1).rolling(
12, min_periods=12
).apply(np.prod, raw=True) - 1
)
)
verify = (
test_data[["date", "ret_12", "direct_ret_12"]]
.dropna()
.tail(5)
.copy()
)
verify["difference"] = (
verify["ret_12"] - verify["direct_ret_12"]
).abs()
verify.round(8)/tmp/ipykernel_260635/922053246.py:28: UserWarning: obj.round has no effect with datetime, timedelta, or period dtypes. Use obj.dt.round(...) instead.| date | ret_12 | direct_ret_12 | difference | |
|---|---|---|---|---|
| 386 | 2023-09-30 | -0.152407 | -0.152407 | 0.0 |
| 387 | 2023-10-31 | -0.208836 | -0.208836 | 0.0 |
| 388 | 2023-11-30 | -0.199018 | -0.199018 | 0.0 |
| 389 | 2023-12-31 | -0.233698 | -0.233698 | 0.0 |
7.8 Việc hủy niêm yết và thiên kiến sống sót
Một vấn đề thực tiễn quan trọng khi tính toán lợi nhuận kép là cách xử lý các chứng khoán bị loại khỏi sàn giao dịch. Việc hủy niêm yết xảy ra vì nhiều lý do: sáp nhập và mua lại, phá sản, không đáp ứng yêu cầu niêm yết, rút lui tự nguyện hoặc chuyển sang sàn giao dịch khác. Nếu lợi nhuận từ việc hủy niêm yết không được tính vào, lợi nhuận kép thu được sẽ bị sai lệch do chọn lọc dữ liệu: chúng đánh giá quá cao hiệu suất vì các kết quả xấu nhất (phá sản, hủy niêm yết bắt buộc) bị loại trừ (Shumway 1997).
7.8.1 Bối cảnh Việt Nam
Tại Việt Nam, chứng khoán có thể bị hủy niêm yết vì nhiều lý do khác nhau theo quy định của Ủy ban Chứng khoán và các quy định của sàn giao dịch:
- Hủy niêm yết bắt buộc: khi một công ty tích lũy lỗ vượt quá vốn điều lệ, không đáp ứng nghĩa vụ báo cáo tài chính trong ba năm liên tiếp hoặc bị thu hồi giấy phép kinh doanh.
- Hủy niêm yết tự nguyện: khi các cổ đông của một công ty bỏ phiếu rút khỏi sàn giao dịch.
- Chuyển đổi: khi một công ty chuyển từ UPCoM sang HOSE/HNX (nâng hạng) hoặc từ HOSE/HNX sang UPCoM (hạ hạng). Những chuyển đổi này không phải là hủy niêm yết thực sự về mặt kinh tế mà cần được xử lý cẩn thận trong việc tính toán lợi nhuận.
Không giống như các thị trường phát triển hơn, nơi dữ liệu về lợi nhuận từ việc hủy niêm yết được biên soạn một cách có hệ thống, dữ liệu thị trường Việt Nam không phải lúc nào cũng cung cấp lợi nhuận rõ ràng từ việc hủy niêm yết. Khi một cổ phiếu bị hủy niêm yết vì lý do chính đáng (ví dụ: phá sản), giá giao dịch cuối cùng có thể đánh giá quá cao giá trị thu hồi của chứng khoán. Các nhà nghiên cứu nên nhận thức được hạn chế này và xem xét việc ước tính lợi nhuận từ việc hủy niêm yết dựa trên lý do hủy niêm yết, theo phương pháp của Shumway (1997).
7.8.2 Tích hợp Lợi nhuận Khi Gỡ Bỏ Niêm yết
Khi một chứng khoán bị gỡ bỏ niêm yết, một “lợi nhuận khi gỡ bỏ niêm yết” cuối cùng sẽ ghi nhận sự thay đổi giá giữa ngày giao dịch thường xuyên cuối cùng và việc thực hiện giá sau khi gỡ bỏ niêm yết. Lợi nhuận này phải được kết hợp với lợi nhuận thông thường trong tháng gỡ bỏ:
\[ R_t^{\text{adj}} = (1 + R_t)(1 + R_t^{\text{delist}}) - 1, \tag{7.12}\]
trong đó \(R_t\) là lợi nhuận thông thường và \(R_t^{\text{delist}}\) là lợi nhuận hủy niêm yết. Nếu thiếu lợi nhuận thông thường (cổ phiếu ngừng giao dịch trước cuối tháng), chúng tôi chỉ sử dụng lợi nhuận hủy niêm yết.
def adjust_for_delisting(df, ret_col="ret_total",
dlret_col="dlret"):
"""Adjust returns for delisting events.
Parameters
----------
df : pd.DataFrame
Must contain `ret_col` and `dlret_col`.
Returns
-------
pd.DataFrame with adjusted return column 'ret_adj'.
"""
df = df.copy()
df["ret_adj"] = df[ret_col]
# Case 1: Both regular and delisting returns available
mask_both = df[ret_col].notna() & df[dlret_col].notna()
df.loc[mask_both, "ret_adj"] = (
(1 + df.loc[mask_both, ret_col]) *
(1 + df.loc[mask_both, dlret_col]) - 1
)
# Case 2: Only delisting return available
mask_dlret_only = (
df[ret_col].isna() & df[dlret_col].notna()
)
df.loc[mask_dlret_only, "ret_adj"] = (
df.loc[mask_dlret_only, dlret_col]
)
return df7.8.3 Tác động của việc điều chỉnh hủy niêm yết
Mức độ sai lệch do hủy niêm yết phụ thuộc vào tần suất và mức độ nghiêm trọng của các sự kiện hủy niêm yết. Shumway (1997) đã chỉ ra rằng, tại các thị trường phát triển, việc bỏ qua lợi nhuận từ hủy niêm yết sẽ tạo ra sai lệch tăng khoảng 1% mỗi năm trong lợi nhuận danh mục đầu tư bình quân gia quyền. Sai lệch này lớn hơn đối với cổ phiếu vốn hóa nhỏ và cổ phiếu giá trị, những loại cổ phiếu dễ gặp khó khăn tài chính hơn. Tại Việt Nam, nơi các công ty nhỏ hơn trên HNX và UPCoM phải đối mặt với những hạn chế thanh khoản chặt chẽ hơn và rủi ro vỡ nợ cao hơn, sai lệch này thậm chí còn rõ rệt hơn. Trong các vụ hủy niêm yết ở thị trường mới nổi, việc hủy niêm yết bắt buộc thường liên quan đến các công ty gặp khó khăn tài chính nghiêm trọng, trong đó giá trị vốn chủ sở hữu còn lại gần bằng không, ngụ ý lợi nhuận từ hủy niêm yết có thể lên tới gần -100% trong trường hợp xấu nhất.
7.9 Ước tính biến động luân chuyển
Biến động lợi nhuận cổ phiếu là yếu tố đầu vào quan trọng đối với quản lý rủi ro, định giá quyền chọn và nhiều mô hình định giá tài sản thực nghiệm. Một phương pháp phổ biến là ước tính độ lệch chuẩn trượt của lợi nhuận trong một khoảng thời gian nhất định.
7.9.1 Biến động luân chuyển 24 tháng
Theo Ben-David, Franzoni, and Moussawi (2012), chúng tôi tính toán độ biến động lợi nhuận tổng thể của cổ phiếu bằng độ lệch chuẩn luân chuyển của lợi nhuận hàng tháng trong khoảng thời gian 24 tháng:
\[ \hat{\sigma}_{i,t}^{24} = \sqrt{\frac{1}{23}\sum_{j=0}^{23}(R_{i,t-j} - \bar{R}_{i,t}^{24})^2}, \tag{7.13}\]
trong đó \(\bar{R}_{i,t}^{24} = \frac{1}{24}\sum_{j=0}^{23} R_{i,t-j}\) là lợi nhuận trung bình trong 24 tháng gần nhất.
def rolling_volatility(df, ret_col="ret_total",
group_col="symbol",
window=24):
"""Compute rolling return volatility.
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
window : int
Rolling window length in periods.
Returns
-------
pd.DataFrame with 'vol_{window}' column (annualized).
"""
df = df.sort_values([group_col, "date"]).copy()
df[f"vol_{window}"] = (
df.groupby(group_col)[ret_col]
.transform(
lambda x: x.rolling(
window=window, min_periods=window
).std()
)
)
# Annualize (monthly to annual)
df[f"vol_{window}_ann"] = df[f"vol_{window}"] * np.sqrt(12)
return dfstock_vol = rolling_volatility(stock_rolling)Figure 7.3 thể hiện sự phân bố theo mặt cắt ngang của độ biến động hàng năm trong 24 tháng theo thời gian.
vol_stats = (
stock_vol
.dropna(subset=["vol_24_ann"])
.groupby("date")["vol_24_ann"]
.agg(["median", lambda x: x.quantile(0.25),
lambda x: x.quantile(0.75)])
.reset_index()
)
vol_stats.columns = ["date", "median", "p25", "p75"]
plot_vol = (
ggplot(vol_stats, aes(x="date")) +
geom_ribbon(aes(ymin="p25", ymax="p75"),
alpha=0.3, fill="#b2182b") +
geom_line(aes(y="median"), color="#b2182b", size=0.7) +
labs(x="", y="Annualized 24-month volatility") +
scale_y_continuous(labels=percent_format()) +
theme_minimal() +
theme(figure_size=(10, 5))
)
plot_vol.draw()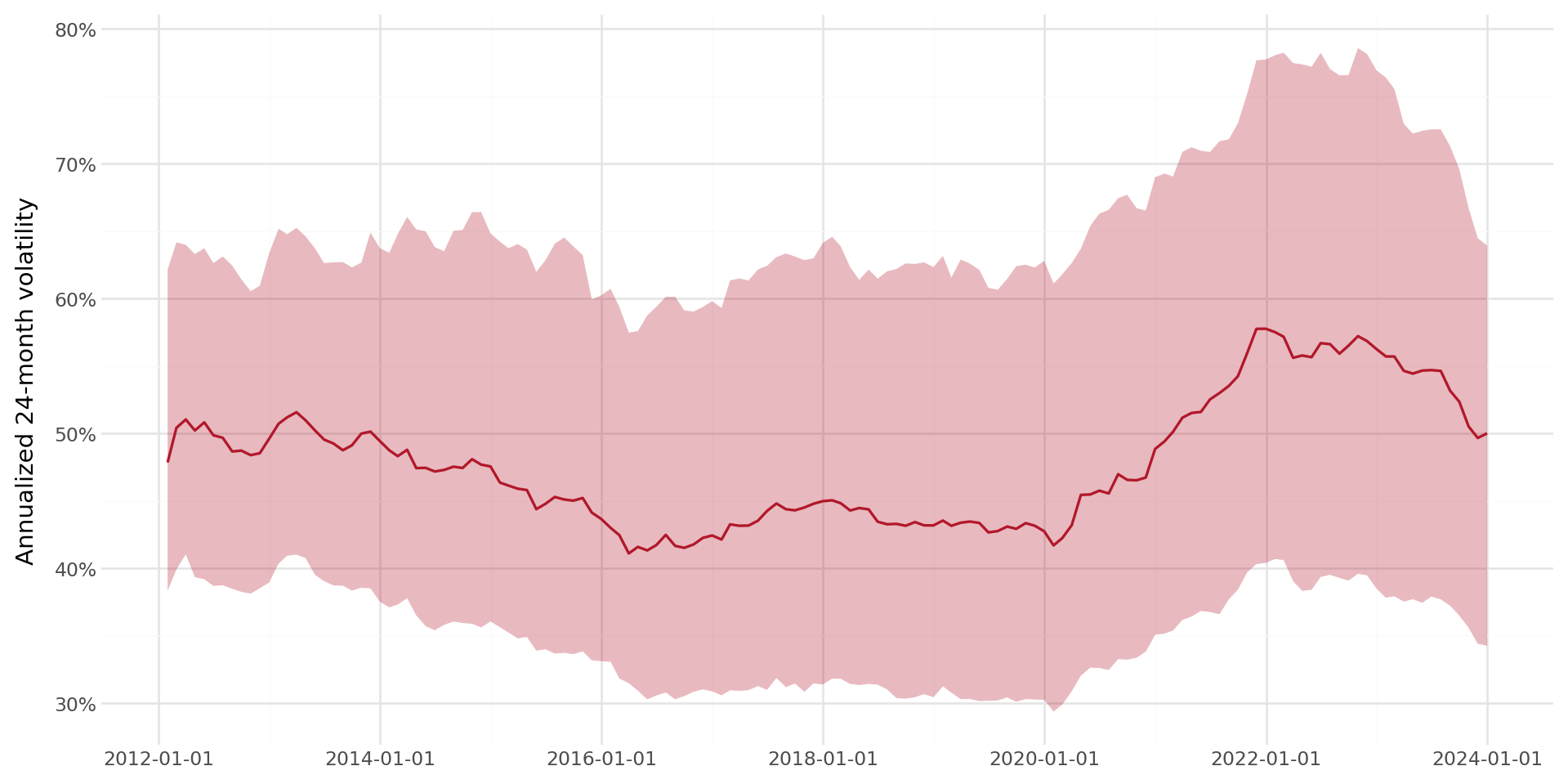
7.9.2 Biến động và lợi nhuận kép: Sự hao hụt phương sai
Như đã lưu ý trong Equation 7.7, lợi nhuận trung bình hình học thấp hơn lợi nhuận trung bình số học khoảng \(\sigma^2/2\). Hiện tượng “giảm phương sai” hay “sức cản biến động” này có nghĩa là hai danh mục đầu tư có cùng lợi nhuận trung bình số học nhưng độ biến động khác nhau sẽ có lợi nhuận kép khác nhau: danh mục đầu tư có độ biến động thấp hơn sẽ tích lũy được nhiều tài sản hơn ở giai đoạn cuối kỳ.
Hiệu ứng này có ý nghĩa quan trọng về mặt định lượng ở Việt Nam. Một cổ phiếu có lợi nhuận trung bình hàng tháng là 1,5% và độ lệch chuẩn hàng tháng là 10% sẽ chịu ảnh hưởng bởi sự biến động khoảng 0,10^2/2 = 0,5% mỗi tháng, hoặc khoảng 6% mỗi năm. Điều này phù hợp với quan sát cho thấy các nhà đầu tư Việt Nam đang phải đối mặt với sự suy giảm đáng kể về giá trị tài sản tích lũy do sự biến động cao của từng cổ phiếu riêng lẻ. Chúng ta có thể kiểm chứng điều này bằng thực nghiệm bằng cách phân loại cổ phiếu theo nhóm biến động và so sánh lợi nhuận tích lũy:
annual_data = compound_return_by_period(
prices_monthly, period="year"
)
annual_data = annual_data[annual_data["n_obs"] >= 10].copy()
vol_annual = (
prices_monthly
.groupby(["symbol", prices_monthly["date"].dt.year])[
"ret_total"
]
.agg(["std", "mean", "count"])
.reset_index()
)
vol_annual.columns = ["symbol", "period", "monthly_std",
"monthly_mean", "n_months"]
vol_annual = vol_annual[vol_annual["n_months"] >= 10].copy()
vol_annual["ann_vol"] = vol_annual["monthly_std"] * np.sqrt(12)
vol_annual["arith_mean_ann"] = vol_annual["monthly_mean"] * 12
vol_analysis = annual_data.merge(
vol_annual, on=["symbol", "period"]
)
vol_analysis["vol_quintile"] = (
vol_analysis.groupby("period")["ann_vol"]
.transform(
lambda x: pd.qcut(
x, 5, labels=[1, 2, 3, 4, 5], duplicates="drop"
)
)
)
vol_summary = (
vol_analysis
.groupby("vol_quintile")
.agg(
arithmetic_mean=("arith_mean_ann", "mean"),
geometric_mean=("cumret", "mean"),
avg_volatility=("ann_vol", "mean"),
n_stockyears=("cumret", "count")
)
.round(4)
.reset_index()
)
vol_summary| vol_quintile | arithmetic_mean | geometric_mean | avg_volatility | n_stockyears | |
|---|---|---|---|---|---|
| 0 | 1 | -0.0908 | -0.0763 | 0.1887 | 2708 |
| 1 | 2 | -0.0754 | -0.0610 | 0.3312 | 2700 |
| 2 | 3 | -0.0388 | -0.0169 | 0.4493 | 2701 |
| 3 | 4 | 0.0404 | 0.0494 | 0.6005 | 2700 |
| 4 | 5 | 0.4411 | 0.3389 | 1.0288 | 2705 |
7.10 Lợi nhuận kép vào thời điểm kết thúc năm tài chính
Một phương pháp được sử dụng rộng rãi trong nghiên cứu kế toán và tài chính là liên kết lợi nhuận kép với ngày kết thúc kỳ kế toán cụ thể của từng công ty. Điều này rất cần thiết để tính toán lợi nhuận bất thường khi mua và nắm giữ (BHAR) cho các nghiên cứu sự kiện, sự biến động sau khi công bố lợi nhuận và các nghiên cứu khác mà ngày xảy ra sự kiện khác nhau tùy thuộc vào từng công ty.
Tại Việt Nam, đa số các công ty niêm yết tuân theo năm tài chính dương lịch (tháng 1 – tháng 12), theo quy định của Luật Kế toán, trừ trường hợp được Bộ Tài chính miễn trừ. Tuy nhiên, các công ty trong một số ngành (ví dụ: nông nghiệp, du lịch) có thể sử dụng năm tài chính không theo chuẩn, kết thúc vào tháng 3, tháng 6 hoặc tháng 9.
7.10.1 Điều chỉnh lợi nhuận phù hợp với các kỳ kế toán
Thách thức chính là thời điểm kết thúc năm tài chính khác nhau giữa các công ty. Chúng ta cần tính toán lợi nhuận kép trong các khoảng thời gian được xác định dựa trên các ngày cụ thể của từng công ty.
def compound_returns_around_event(
returns_df, events_df,
id_col="symbol", date_col="date",
event_date_col="datadate", ret_col="ret_total",
pre_windows=[3, 6, 9, 12],
post_windows=[3, 6]
):
"""Compute compound returns in windows around firm-specific
event dates.
Parameters
----------
returns_df : pd.DataFrame
Monthly returns with [id_col, date_col, ret_col].
events_df : pd.DataFrame
Event dates with [id_col, event_date_col].
pre_windows : list of int
Trailing window lengths (months before event).
post_windows : list of int
Forward window lengths (months after event).
Returns
-------
pd.DataFrame with compound returns for each window.
"""
returns_df = returns_df.sort_values(
[id_col, date_col]
).copy()
events_df = events_df.copy()
# Align event dates to month ends
events_df["event_month"] = (
pd.to_datetime(events_df[event_date_col])
+ pd.offsets.MonthEnd(0)
)
results = []
for _, event in events_df.iterrows():
sid = event[id_col]
edate = event["event_month"]
sec_rets = returns_df[
returns_df[id_col] == sid
].copy()
sec_rets = sec_rets.set_index(date_col)[ret_col]
row = {id_col: sid,
event_date_col: event[event_date_col]}
# Pre-event compound returns
for k in pre_windows:
start = edate - pd.DateOffset(months=k-1)
start = (start - pd.offsets.MonthEnd(0)
+ pd.offsets.MonthEnd(0))
window_rets = sec_rets[
(sec_rets.index >= start)
& (sec_rets.index <= edate)
]
if len(window_rets) >= k * 0.8:
cumret = (
np.exp(np.log(1 + window_rets).sum()) - 1
)
else:
cumret = np.nan
row[f"ret_pre_{k}"] = cumret
# Post-event compound returns
for k in post_windows:
start = edate + pd.DateOffset(months=1)
end = (edate + pd.DateOffset(months=k)
+ pd.offsets.MonthEnd(0))
window_rets = sec_rets[
(sec_rets.index >= start)
& (sec_rets.index <= end)
]
if len(window_rets) >= k * 0.8:
cumret = (
np.exp(np.log(1 + window_rets).sum()) - 1
)
else:
cumret = np.nan
row[f"ret_post_{k}"] = cumret
results.append(row)
return pd.DataFrame(results)7.10.2 Lợi nhuận bất thường khi mua và nắm giữ so với lợi nhuận bất thường tích lũy
Đối với các nghiên cứu sự kiện và đánh giá hiệu suất, chúng ta thường muốn có lợi nhuận kép vượt trội, tức là lợi nhuận kép của cổ phiếu trừ đi lợi nhuận kép của chỉ số tham chiếu trong cùng khoảng thời gian. Lợi nhuận bất thường khi mua và nắm giữ (BHAR) được định nghĩa là
\[ \text{BHAR}_{i,t}(k) = \prod_{j=1}^{k}(1 + R_{i,t+j}) - \prod_{j=1}^{k}(1 + R_{b,t+j}), \tag{7.14}\]
trong đó \(R_{b,t}\) là lợi suất chuẩn (chỉ số thị trường, danh mục đầu tư phù hợp quy mô, v.v.). Điều này khác với lợi suất bất thường tích lũy (CAR), là tổng của các lợi suất bất thường đơn giản:
\[ \text{CAR}_{i,t}(k) = \sum_{j=1}^{k}(R_{i,t+j} - R_{b,t+j}). \tag{7.15}\]
BHAR phản ánh tốt hơn trải nghiệm thực tế của nhà đầu tư vì nó thể hiện sự tích lũy lợi nhuận, trong khi CAR ngầm giả định việc tái cân bằng hàng ngày để duy trì vị thế bằng nhau về giá trị đô la trong cổ phiếu và chỉ số tham chiếu (Barber and Lyon 1997). Sự khác biệt này đặc biệt quan trọng ở Việt Nam, nơi lợi nhuận của từng cổ phiếu có thể biến động mạnh và do đó hiệu ứng tích lũy được khuếch đại. Lyon, Barber, and Tsai (1999) cung cấp thêm phân tích về các đặc tính thống kê của BHAR và đề xuất các giá trị tới hạn được lấy mẫu bằng phương pháp bootstrap để suy luận.
def compute_bhar(stock_returns, benchmark_returns):
"""Compute buy-and-hold abnormal return.
Parameters
----------
stock_returns : array-like
Sequence of stock returns.
benchmark_returns : array-like
Sequence of benchmark returns (same length).
Returns
-------
float : BHAR
"""
stock_cumret = (
np.prod(1 + np.array(stock_returns)) - 1
)
bench_cumret = (
np.prod(1 + np.array(benchmark_returns)) - 1
)
return stock_cumret - bench_cumret7.11 Giá trị sổ sách của vốn chủ sở hữu
Nhiều ứng dụng thực nghiệm sử dụng lợi nhuận kép cũng yêu cầu các biến kế toán cấp doanh nghiệp. Một biến thường được sử dụng là giá trị sổ sách của vốn chủ sở hữu, được tính toán theo Daniel and Titman (1997):
\[ \text{BE} = \text{SE} + \text{DT} + \text{ITC} - \text{PS}, \tag{7.16}\]
Trong đó, SE là vốn chủ sở hữu, DT là thuế hoãn lại, ITC là tín dụng thuế đầu tư và PS là giá trị cổ phiếu ưu đãi. Đối với cổ phiếu ưu đãi, thứ tự ưu tiên là: giá trị mua lại (nếu có), sau đó là giá trị thanh lý, rồi đến giá trị ghi sổ.
Tại Việt Nam, các chuẩn mực kế toán (Chuẩn mực kế toán Việt Nam, VAS, và ngày càng nhiều trường hợp áp dụng IFRS) đưa ra một hệ thống tài khoản hơi khác. Vốn chủ sở hữu được báo cáo trên bảng cân đối kế toán là Vốn chủ sở hữu, bao gồm vốn góp của chủ sở hữu, thặng dư vốn cổ phần, điều chỉnh cổ phiếu quỹ, lợi nhuận giữ lại chưa phân phối và các khoản dự trữ khác. Tài sản và nợ thuế hoãn lại được báo cáo riêng. Cổ phiếu ưu đãi khá hiếm gặp ở các công ty niêm yết của Việt Nam (hầu hết chỉ phát hành cổ phiếu phổ thông), nhưng khi có, giá trị sổ sách của nó cần được trừ khỏi tổng vốn chủ sở hữu.
def compute_book_equity(df):
"""Compute book value of equity for Vietnamese firms.
Parameters
----------
df : pd.DataFrame
Must contain at minimum: equity (stockholders' equity),
deferred_tax (deferred tax liabilities, net),
pref_stock (preferred stock, if applicable).
Returns
-------
pd.DataFrame with 'be' column.
"""
df = df.copy()
df["pref"] = df.get(
"pref_stock", pd.Series(0, index=df.index)
)
df["dt"] = df.get(
"deferred_tax", pd.Series(0, index=df.index)
)
df["be"] = (
df["equity"].fillna(0)
+ df["dt"].fillna(0)
- df["pref"].fillna(0)
)
# Set non-positive book equity to NaN
df.loc[df["be"] <= 0, "be"] = np.nan
return df7.12 Mức giảm tối đa
Mức sụt giảm tối đa là một chỉ số rủi ro quan trọng bổ sung cho biến động. Trong khi biến động đo lường sự phân tán lợi nhuận một cách đối xứng, mức sụt giảm tối đa thể hiện mức lỗ tích lũy tồi tệ nhất mà nhà đầu tư có thể gặp phải: một thước đo phù hợp hơn với cách nhà đầu tư cảm nhận rủi ro về mặt tâm lý (Kahneman and Tversky 2013).
def compute_max_drawdown(df, ret_col="ret_total",
group_col="symbol"):
"""Compute maximum drawdown for each security.
Parameters
----------
df : pd.DataFrame
ret_col : str
group_col : str
Returns
-------
pd.DataFrame with 'max_drawdown' and running drawdown.
"""
df = df.sort_values([group_col, "date"]).copy()
df["gross_ret"] = 1 + df[ret_col]
df["wealth"] = (
df.groupby(group_col)["gross_ret"].cumprod()
)
df["peak"] = df.groupby(group_col)["wealth"].cummax()
df["drawdown"] = (
(df["wealth"] - df["peak"]) / df["peak"]
)
max_dd = (
df.groupby(group_col)["drawdown"]
.min()
.reset_index(name="max_drawdown")
)
df = df.merge(max_dd, on=group_col)
df.drop(columns=["gross_ret"], inplace=True)
return dfFigure 35.7 minh họa biểu đồ giảm giá trị cổ phiếu đã chọn.
dd_data = compute_max_drawdown(
prices_monthly[
prices_monthly["symbol"] == long_history_stocks[0]
]
)
mdd = dd_data["max_drawdown"].iloc[0]
plot_dd = (
ggplot(dd_data, aes(x="date", y="drawdown")) +
geom_area(fill="#b2182b", alpha=0.4) +
geom_line(color="#b2182b", size=0.5) +
geom_hline(yintercept=mdd, linetype="dashed") +
labs(x="", y="Drawdown from peak") +
scale_y_continuous(labels=percent_format()) +
theme_minimal() +
theme(figure_size=(10, 4))
)
plot_dd.draw()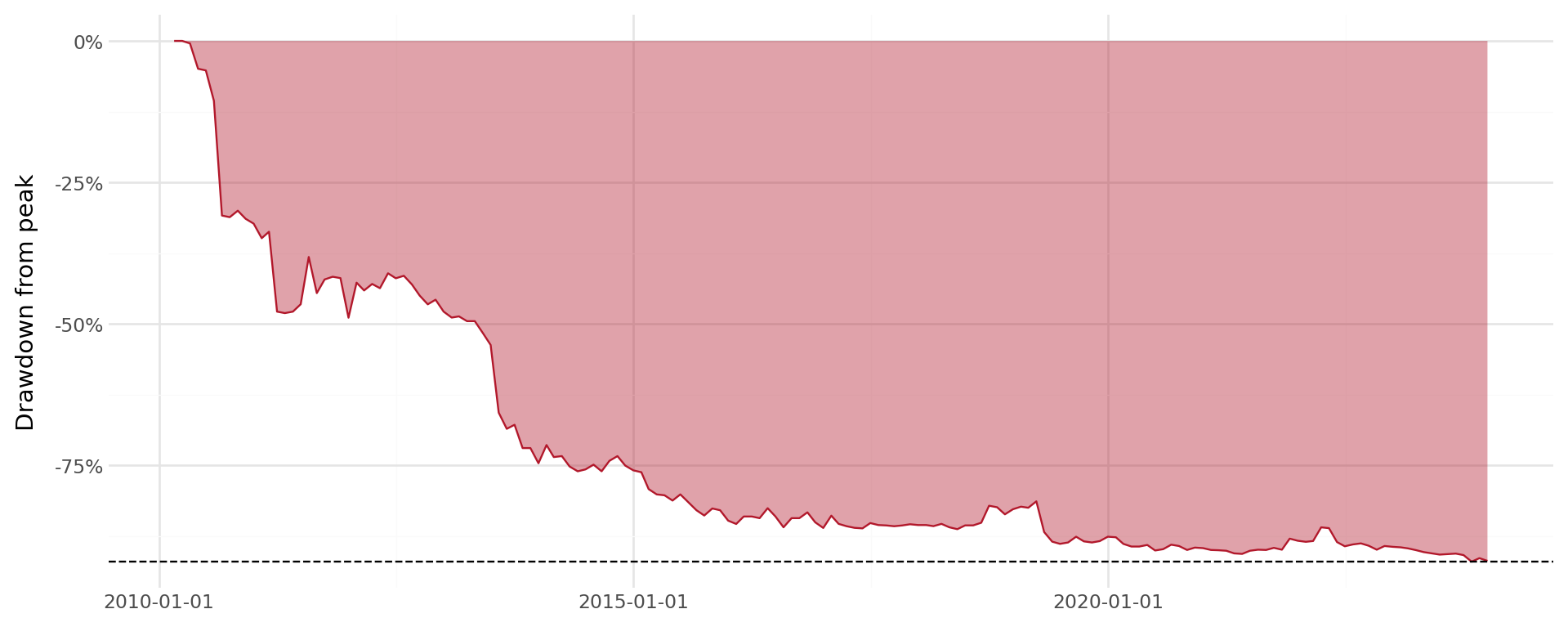
7.13 Kết hợp tất cả lại với nhau: Một quy trình toàn diện
Giờ đây, chúng tôi kết hợp tất cả các phương pháp vào một quy trình duy nhất để tạo ra một tập dữ liệu sẵn sàng nghiên cứu với lợi nhuận kép luân phiên, lợi nhuận thị trường, biến động và các biện pháp sụt giảm.
def build_compound_return_dataset(
stock_df, windows=[3, 6, 9, 12], vol_window=24
):
"""Build comprehensive compound return dataset.
Parameters
----------
stock_df : pd.DataFrame
Monthly stock return data with columns:
symbol, date, ret_total, mkt_total.
windows : list of int
Rolling compound return windows.
vol_window : int
Rolling volatility window.
Returns
-------
pd.DataFrame
"""
df = stock_df.sort_values(["symbol", "date"]).copy()
# Step 1: Log returns
df["log_ret"] = np.log(1 + df["ret_total"])
df["log_mkt"] = np.log(1 + df["mkt_total"])
# Step 2: Rolling compound returns (stock and market)
for k in windows:
df[f"ret_{k}"] = np.exp(
df.groupby("symbol")["log_ret"]
.transform(
lambda x: x.rolling(k, min_periods=k).sum()
)
) - 1
df[f"mkt_{k}"] = np.exp(
df["log_mkt"]
.rolling(k, min_periods=k)
.sum()
) - 1
# Excess compound return (BHAR vs market)
df[f"exret_{k}"] = df[f"ret_{k}"] - df[f"mkt_{k}"]
# Step 3: Cumulative return (full history)
df["wealth"] = (
df.groupby("symbol")["log_ret"]
.cumsum()
.apply(np.exp)
)
df["cumret"] = df["wealth"] - 1
# Step 4: Rolling volatility
df[f"vol_{vol_window}"] = (
df.groupby("symbol")["ret_total"]
.transform(
lambda x: x.rolling(
vol_window, min_periods=vol_window
).std()
)
) * np.sqrt(12) # annualize
# Step 5: Drawdown
df["peak"] = df.groupby("symbol")["wealth"].cummax()
df["drawdown"] = (df["wealth"] - df["peak"]) / df["peak"]
# Clean up
df.drop(
columns=["log_ret", "log_mkt", "peak"], inplace=True
)
return df# Build the full dataset
compound_dataset = build_compound_return_dataset(prices_monthly)Table 7.7 cung cấp số liệu thống kê tóm tắt cho các biến chính trong tập dữ liệu lợi nhuận kép.
summary_cols = ["ret_total", "ret_3", "ret_6", "ret_12",
"exret_3", "exret_12", "vol_24", "drawdown"]
available_cols = [c for c in summary_cols
if c in compound_dataset.columns]
summary = (
compound_dataset[available_cols]
.describe(percentiles=[0.05, 0.25, 0.50, 0.75, 0.95])
.T
.round(4)
)
summary| count | mean | std | min | 5% | 25% | 50% | 75% | 95% | max | |
|---|---|---|---|---|---|---|---|---|---|---|
| ret_total | 165499.0 | 0.0042 | 0.1862 | -0.9900 | -0.2381 | -0.0703 | 0.0000 | 0.0553 | 0.2773 | 12.7500 |
| ret_3 | 162586.0 | 0.0094 | 0.3393 | -0.9999 | -0.3889 | -0.1436 | -0.0126 | 0.0987 | 0.5000 | 27.2911 |
| ret_6 | 158227.0 | 0.0171 | 0.5053 | -0.9999 | -0.5095 | -0.2196 | -0.0400 | 0.1404 | 0.7320 | 35.7136 |
| ret_12 | 149520.0 | 0.0375 | 0.8136 | -0.9999 | -0.6522 | -0.3191 | -0.0877 | 0.1807 | 1.0767 | 47.9515 |
| exret_3 | 153637.0 | 0.0385 | 0.3343 | -1.1691 | -0.3420 | -0.1163 | 0.0067 | 0.1378 | 0.4992 | 27.3041 |
| exret_12 | 140571.0 | 0.1401 | 0.8031 | -1.5858 | -0.5388 | -0.2003 | 0.0281 | 0.2880 | 1.1119 | 48.0488 |
| vol_24 | 132233.0 | 0.5493 | 0.3488 | 0.0000 | 0.2070 | 0.3445 | 0.4827 | 0.6737 | 1.0739 | 9.1792 |
| drawdown | 165499.0 | -0.5927 | 0.2975 | -1.0000 | -0.9631 | -0.8501 | -0.6616 | -0.3725 | 0.0000 | 0.0000 |
7.14 Phân bố theo mặt cắt ngang của lợi nhuận kép
Để hiểu rõ sự khác biệt về lợi nhuận kép giữa các loại chứng khoán, chúng tôi xem xét phân bố theo mặt cắt ngang ở các khoảng thời gian khác nhau.
horizon_data = pd.DataFrame()
for k in [3, 6, 12]:
col = f"ret_{k}"
temp = compound_dataset[[col]].dropna().copy()
temp.columns = ["compound_return"]
temp["horizon"] = f"{k} months"
lo, hi = temp["compound_return"].quantile([0.01, 0.99])
temp = temp[
(temp["compound_return"] >= lo)
& (temp["compound_return"] <= hi)
]
horizon_data = pd.concat([horizon_data, temp])
plot_horizons = (
ggplot(horizon_data,
aes(x="compound_return", fill="horizon")) +
geom_density(alpha=0.4) +
geom_vline(xintercept=0, linetype="dashed") +
labs(x="Compound return", y="Density", fill="Horizon") +
scale_x_continuous(labels=percent_format()) +
theme_minimal() +
theme(legend_position="bottom",
figure_size=(10, 5))
)
plot_horizons.draw()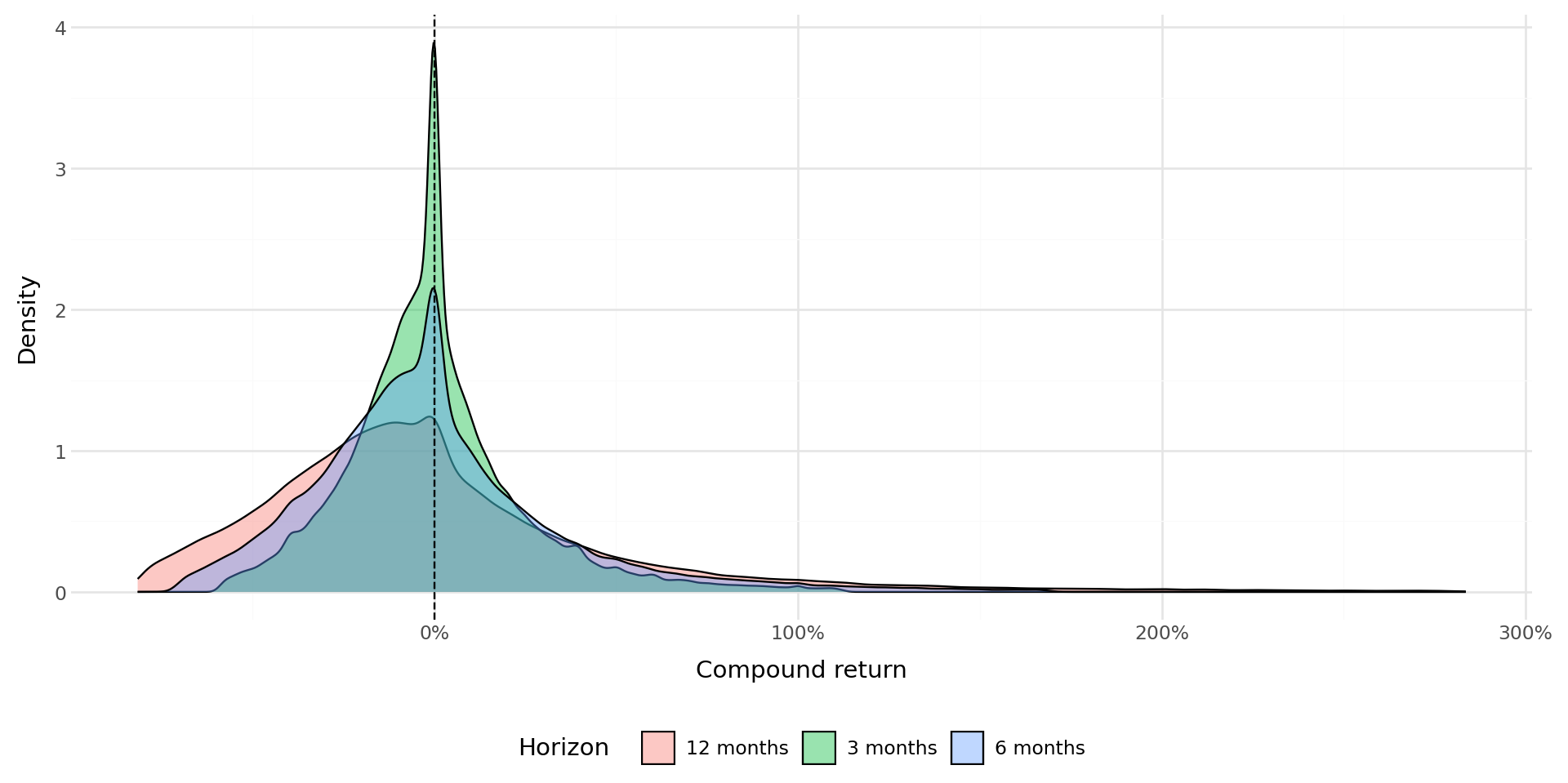
7.15 Cân nhắc cụ thể tại Việt Nam
7.15.1 Giới hạn giá và ảnh hưởng của chúng đối với lãi kép
Các sàn giao dịch chứng khoán Việt Nam áp đặt giới hạn giá hàng ngày giới hạn sự thay đổi giá tối đa so với giá tham chiếu. Theo quy định mới nhất:
- HOSE: \(\pm 7\%\)
- HNX: \(\pm 10\%\)
- UPCoM: \(\pm 15\%\)
Các giới hạn này cắt bớt phân phối lợi nhuận hàng ngày và có thể tạo ra chuỗi các ngày đạt giới hạn khi các sự kiện thông tin lớn xảy ra. Đối với tính toán lợi nhuận kép, điều này có nghĩa là việc điều chỉnh thông tin mới có thể được trải rộng trong nhiều ngày thay vì xảy ra ngay lập tức. Khi tính toán lợi nhuận kép hàng tháng từ dữ liệu hàng ngày, điều này được xử lý chính xác vì lợi nhuận kép tích lũy toàn bộ điều chỉnh bất kể mất bao nhiêu ngày.
Tuy nhiên, giới hạn giá có thể gây ra sai lệch trong các tính toán lợi nhuận ngắn hạn. Nếu một sự kiện tích cực lớn xảy ra và cổ phiếu chạm mức trần giới hạn trong vài ngày liên tiếp, lợi nhuận kép trong 1 ngày hoặc 1 tuần sẽ đánh giá thấp nội dung thông tin thực sự của sự kiện (Kim, Liu, and Yang 2013). Đối với các ứng dụng nghiên cứu sự kiện, các nhà nghiên cứu nên xác minh rằng cửa sổ sự kiện đủ dài để phù hợp với sự chậm trễ do giới hạn giá gây ra trong việc điều chỉnh giá.
7.15.2 Giới hạn sở hữu nước ngoài
Việt Nam áp đặt giới hạn sở hữu nước ngoài (FOL) đối với các công ty niêm yết, thường giới hạn ở mức 49% đối với hầu hết các ngành và thấp hơn (30% hoặc ít hơn) đối với một số lĩnh vực bị hạn chế như ngân hàng và viễn thông. Khi một cổ phiếu đạt đến FOL, các nhà đầu tư nước ngoài chỉ có thể mua cổ phiếu từ những người bán nước ngoài khác, tạo ra một thị trường cao cấp song song cho cổ phiếu hội đồng quản trị nước ngoài. Điều này không ảnh hưởng trực tiếp đến việc tính toán lợi nhuận kép (sử dụng giá giao dịch chính thức), nhưng các nhà nghiên cứu nghiên cứu lợi nhuận danh mục đầu tư xuyên biên giới nên lưu ý rằng giá hiệu quả mà các nhà đầu tư nước ngoài trả có thể khác với giá bảng (Vo 2017).
7.15.3 Chỉ số VN-Index và các điểm chuẩn thị trường
Đối với lợi nhuận kép chuẩn, các chỉ số chính của Việt Nam là:
- VN-Index: Chỉ số tính theo giá trị vốn hóa của tất cả các cổ phiếu niêm yết trên HOSE.
- VN30: 30 cổ phiếu lớn nhất và có tính thanh khoản cao nhất trên HOSE, được soát xét nửa năm.
- HNX-Index: Chỉ số tính theo giá trị vốn hóa của các cổ phiếu niêm yết trên HNX.
VN-Index là điểm chuẩn được sử dụng rộng rãi nhất và là lợi nhuận thị trường mặc định trong bộ dữ liệu của chúng tôi.
7.16 Cân nhắc hiệu suất
Khi làm việc với các tập dữ liệu lớn, hiệu quả tính toán rất quan trọng. Table 7.8 so sánh thời gian thực hiện của bốn phương pháp tổng hợp của chúng tôi trên một tập dữ liệu được tiêu chuẩn hóa.
import time
np.random.seed(42)
n_stocks = 100
n_months = 100
test_df = pd.DataFrame({
"symbol": np.repeat(range(n_stocks), n_months),
"date": np.tile(
pd.date_range("2015-01-31", periods=n_months,
freq="ME"),
n_stocks
),
"ret_total": np.random.normal(
0.01, 0.08, n_stocks * n_months
)
})
methods = {}
t0 = time.time()
_ = compute_cumret_cumprod(test_df)
methods["Cumulative Product"] = time.time() - t0
t0 = time.time()
_ = compute_cumret_logsum(test_df)
methods["Log-Sum-Exp"] = time.time() - t0
t0 = time.time()
_ = compute_cumret_iterative(test_df)
methods["Iterative (carry)"] = time.time() - t0
t0 = time.time()
_ = rolling_compound_return(test_df, windows=[12])
methods["Rolling (12-month)"] = time.time() - t0
perf_df = pd.DataFrame({
"Method": methods.keys(),
"Time (seconds)": [f"{v:.4f}" for v in methods.values()],
"Relative Speed": [
f"{v/min(methods.values()):.1f}x"
for v in methods.values()
]
})
perf_df| Method | Time (seconds) | Relative Speed | |
|---|---|---|---|
| 0 | Cumulative Product | 0.0068 | 1.1x |
| 1 | Log-Sum-Exp | 0.0064 | 1.0x |
| 2 | Iterative (carry) | 0.4896 | 76.2x |
| 3 | Rolling (12-month) | 0.0267 | 4.1x |
7.17 Những lỗi thường gặp và cách làm tốt nhất
Một số vấn đề nhỏ có thể dẫn đến tính toán lợi nhuận kép không chính xác. Chúng tôi tóm tắt những vấn đề quan trọng nhất như sau:
Khoảng trống trong chuỗi thời gian. Nếu một chứng khoán có những tháng không có dữ liệu quan sát (thậm chí không có cờ báo lợi nhuận bị thiếu), các phép tính cửa sổ trượt dựa trên chỉ số vị thế sẽ cho ra kết quả không chính xác. Cửa sổ trượt sẽ bao phủ khoảng thời gian không đúng. Luôn đảm bảo chuỗi thời gian đầy đủ, điền vào các khoảng trống bằng các giá trị bị thiếu rõ ràng trước khi tính toán số liệu thống kê trượt. Điều này đặc biệt quan trọng ở Việt Nam, nơi việc tạm ngừng giao dịch có thể tạo ra các khoảng trống.
Sai lệch do chọn lọc chứng khoán còn tồn tại. Như đã thảo luận trong phần lợi nhuận từ việc hủy niêm yết, việc loại trừ các chứng khoán ngừng giao dịch sẽ làm sai lệch lợi nhuận kép theo hướng tăng lên. Luôn luôn kết hợp lợi nhuận từ việc hủy niêm yết khi có sẵn. Khi không có lợi nhuận từ việc hủy niêm yết (như đôi khi xảy ra với dữ liệu của Việt Nam), hãy xem xét sử dụng các giá trị ước tính dựa trên lý do hủy niêm yết.
Thiên kiến nhìn xa trông rộng. Khi điều chỉnh lợi nhuận kép theo cuối năm tài chính cho phân tích chéo, cần thận trọng không sử dụng lợi nhuận trước khi kết thúc năm tài chính để dự đoán lợi nhuận sau khi công bố kết quả. Các doanh nghiệp Việt Nam bắt buộc phải công bố báo cáo tài chính thường niên đã được kiểm toán trong vòng 90 ngày kể từ ngày kết thúc năm tài chính, vì vậy nên có khoảng thời gian đệm ít nhất 3 tháng khi xây dựng lợi nhuận kép hướng tới tương lai.
Lỗi tràn và thiếu số liệu. Đối với các kỳ tính lãi kép rất dài hoặc lợi nhuận cực đoan, tích lũy có thể bị tràn (vô cực) hoặc thiếu (0). Phương pháp log-sum-exp mạnh mẽ hơn đối với các vấn đề số học như vậy vì nó hoạt động trong không gian logarit, nơi phạm vi được thu hẹp.
Tính toán lợi nhuận hàng năm từ các kỳ không đầy đủ. Khi tính toán lợi nhuận hàng năm từ dữ liệu của các kỳ không đầy đủ (ví dụ: dữ liệu 7 tháng được tính toán hàng năm thành 12 tháng), công thức tính toán lợi nhuận hàng năm \((1+R)^{12/k} - 1\) giả định rằng tỷ suất lợi nhuận quan sát được sẽ không thay đổi. Giả định này càng mạnh mẽ hơn đối với các kỳ không đầy đủ ngắn và có thể dẫn đến kết quả sai lệch. Hãy báo cáo tỷ suất lợi nhuận kép thực tế và số kỳ cùng với bất kỳ con số lợi nhuận hàng năm nào.
Chuyển nhượng cổ phiếu. Tại Việt Nam, cổ phiếu đôi khi được chuyển nhượng giữa các sàn UPCoM, HNX và HOSE. Việc chuyển nhượng này có thể dẫn đến việc tạm ngừng giao dịch và gây ra những khoảng trống rõ ràng trong chuỗi lợi nhuận. Khi tính toán lợi nhuận kép trải qua quá trình chuyển nhượng, cần đảm bảo chuỗi lợi nhuận liên tục kể từ ngày chuyển nhượng.