Firm Valuation#
Valuing a private firm can be more challenging than valuing a public firm due to the lack of readily available financial data, but there are several established methods that can help you arrive at a reasonable estimate. Here are some common approaches Finance Perspective::
1. Comparable Company Analysis (Market Multiples)#
Process: Identify similar publicly traded companies and apply their valuation multiples (e.g., Price/Earnings, Price/Sales, or EV/EBITDA) to the private company.
Steps:
Find public firms that operate in the same industry, have similar business models, and are of comparable size.
Calculate the valuation multiples for these public firms (e.g., Enterprise Value/EBITDA, Price/Earnings ratio).
Apply these multiples to the private firm’s financial metrics (e.g., earnings, sales).
Adjust for differences in size, growth prospects, and risk between the private and public firms.
Challenges: Adjustments for liquidity and size are often required, as private firms are typically riskier and less liquid than publfirms.
2. Discounted Cash Flow (DCF) Analysis#
Process: Estimate the future free cash flows of the company and discount them to present value using an appropriate discount rate (often the firm’s weighted average cost of capital, or WACC).
Steps:
Forecast the firm’s free cash flows (FCF) for a certain period (usually 5-10 years).
Estimate the terminal value, which represents the value of the firm beyond the forecast period.
Discount the projected cash flows and terminal value back to present value using the discount rate (WACC).
Adjust for any debt or excess cash to arrive at an equity valuation.
Challenges: Requires detailed financial projections and a reliable discount rate. The assumptions about growth rates and discount rates can significantly imp the valuation.
3. Precedent Transactions Analysis#
Process: Look at the prices paid for similar companies in recent transactions (mergers and acquisitions) and apply those multiples to the private firm.
Steps:
Identify recent transactions of similar firms in the same industry.
Extract valuation multiples from these transactions (e.g., EV/EBITDA, EV/Sales).
Apply these multiples to the private firm’s financials to estimate its value.
Challenges: Finding truly comparable transactions and adjusting for timing differences, as market conditions may have changednce those transactions.
4. Asset-Based Valuation#
Process: Value the company based on the net value of its assets (assets minus liabilities).
Steps:
Sum up the fair market value of all the company’s tangible and intangible assets.
Subtract any liabilities to determine the net asset value.
Challenges: This method works well for asset-heavy firms but may undervalue firms with significant intangible assets (e.g., intectual property, brand value).
5. Earnings Capitalization Method#
Process: Use a company’s historical earnings and capitalize them at a rate that reflects the risk of the business.
Steps:
Determine the firm’s normalized earnings (e.g., after adjusting for non-recurring events).
Select an appropriate capitalization rate based on the firm’s risk profile.
Value the firm by dividing normalized earnings by the capitalization rate.
Challenges: This method is more static andy not reflect future growth prospects.
6. Private Equity Valuation#
Process: Use private equity benchmarks, considering factors such as control premiums, illiquidity discounts, and expected returns that private equity investors would demand.
Steps:
Estimate future cash flows or earnings.
Apply typical private equity valuation multiples or expected rates of return (IRR) from similar investments.
Challenges: Access data on private equity deals can be limited.
7. Rule of Thumb Valuations#
Process: In some industries, companies are valued based on specific industry rules of thumb (e.g., X times revenue or X times EBITDA).
Steps: Find common valuation benchmarks in the industry and apply them to your firm.
Challenges: These are simplistic and do account for the nuances of individual businesses.
Consider Adjustments for Private Firms:#
Liquidity Discount: Since private firms are harder to sell, a liquidity discount of 10-30% is often applied to the valuation.
Control Premium: If you are valuing a controlling stake, add a control premium (10-40%) to reflect the added value of control.
Size Premium: Smaller firms tend to carry higher n, a combination of methods gives the most comprehensive estimate.
Company |
Start Year |
End Year |
Valuation Growth (%) |
Key Factors |
|---|---|---|---|---|
Tesla |
2019 |
2020 |
740% |
Strong sales, stock splits, and investor optimism in electric vehicles and renewable energy |
Apple |
2019 |
2020 |
85% |
Record-breaking iPhone sales, growth in services, and investor confidence |
Zoom |
2019 |
2020 |
425% |
Increased demand for video conferencing due to COVID-19 pandemic and remote work trends |
NVIDIA |
2015 |
2016 |
224% |
High demand for GPUs in gaming, artificial intelligence (AI), and cryptocurrency mining |
Moderna |
2019 |
2020 |
434% |
Successful progress in COVID-19 vaccine development and mRNA technology |
Amazon |
1998 |
1999 |
1,500% |
Expansion of e-commerce during the dot-com boom |
Beyond Meat |
2018 |
2019 |
200% |
Rapid consumer adoption of plant-based diets and partnerships with fast-food chains and retailers |
Alibaba |
2013 |
2014 |
37% |
Successful IPO and growth in e-commerce and digital payments in China |
Application#
Goal: You are developing a valuation model for private firms using a combination of Graph Neural Networks (GNNs), Long Short-Term Memory networks (LSTMs), and Quantile Regression with LightGBM. The model aims to predict the valuations of private firms based on their features, historical data, and relationships with other firms in the same industry, while adhering to certain constraints derived from public firms’ valuations.
Approach:
Data Preparation: Simulate firm data, including time series features and industry relationships.
Model Components: Build a neural network combining Graph Neural Networks (GNNs) and Long Short-Term Memory networks (LSTMs).
Constraints Application: Enforce valuation caps based on public firms during training and prediction.
Quantile Regression with LightGBM: Estimate valuation ranges using quantile regression.
Adjustments and Final Output: Apply liquidity discounts and control premiums, and present the results.
import numpy as np
import pandas as pd
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
import torch.nn as nn
from torch_geometric.nn import GCNConv
import lightgbm as lgb
import networkx as nx
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import matplotlib.pyplot as plt
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[1], line 2
1 import numpy as np
----> 2 import pandas as pd
3 import os
4 os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
5 import torch
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/__init__.py:22
19 del _hard_dependencies, _dependency, _missing_dependencies
21 # numpy compat
---> 22 from pandas.compat import is_numpy_dev as _is_numpy_dev # pyright: ignore # noqa:F401
24 try:
25 from pandas._libs import hashtable as _hashtable, lib as _lib, tslib as _tslib
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/compat/__init__.py:18
15 from typing import TYPE_CHECKING
17 from pandas._typing import F
---> 18 from pandas.compat.numpy import (
19 is_numpy_dev,
20 np_version_under1p21,
21 )
22 from pandas.compat.pyarrow import (
23 pa_version_under1p01,
24 pa_version_under2p0,
(...) 31 pa_version_under9p0,
32 )
34 if TYPE_CHECKING:
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/compat/numpy/__init__.py:4
1 """ support numpy compatibility across versions """
2 import numpy as np
----> 4 from pandas.util.version import Version
6 # numpy versioning
7 _np_version = np.__version__
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/util/__init__.py:2
1 # pyright: reportUnusedImport = false
----> 2 from pandas.util._decorators import ( # noqa:F401
3 Appender,
4 Substitution,
5 cache_readonly,
6 )
8 from pandas.core.util.hashing import ( # noqa:F401
9 hash_array,
10 hash_pandas_object,
11 )
14 def __getattr__(name):
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/util/_decorators.py:14
6 from typing import (
7 Any,
8 Callable,
9 Mapping,
10 cast,
11 )
12 import warnings
---> 14 from pandas._libs.properties import cache_readonly
15 from pandas._typing import (
16 F,
17 T,
18 )
19 from pandas.util._exceptions import find_stack_level
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/_libs/__init__.py:13
1 __all__ = [
2 "NaT",
3 "NaTType",
(...) 9 "Interval",
10 ]
---> 13 from pandas._libs.interval import Interval
14 from pandas._libs.tslibs import (
15 NaT,
16 NaTType,
(...) 21 iNaT,
22 )
File pandas/_libs/interval.pyx:1, in init pandas._libs.interval()
----> 1 'Could not get source, probably due dynamically evaluated source code.'
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
Data Preparation#
Simulate a dataset that reflects real-world scenarios involving public and private firms, their industries, time series features, and inter-firm relationships.
# Parameters
NUM_FIRMS = 1000
NUM_PUBLIC = 100
NUM_INDUSTRIES = 5
YEARS = 5
FEATURES_PER_YEAR = 5
GROWTH_CAP_MULTIPLIER = 15 # 1500% growth
# Generate firm IDs and assign industries
firm_ids = np.arange(NUM_FIRMS)
industries = np.random.choice(range(NUM_INDUSTRIES), NUM_FIRMS)
# Assign public/private status
is_public = np.array([True]*NUM_PUBLIC + [False]*(NUM_FIRMS - NUM_PUBLIC))
# Generate time series data
np.random.seed(42) # For reproducibility
time_series_data = np.random.randn(NUM_FIRMS, YEARS, FEATURES_PER_YEAR)
# Generate network connections within the same industry
G = nx.Graph()
G.add_nodes_from(firm_ids)
for industry in range(NUM_INDUSTRIES):
firms_in_industry = firm_ids[industries == industry]
if len(firms_in_industry) > 1:
edges = list(nx.fast_gnp_random_graph(len(firms_in_industry), 0.1, seed=industry).edges())
edges = [(firms_in_industry[u], firms_in_industry[v]) for u, v in edges]
G.add_edges_from(edges)
# Create edge_index for PyTorch Geometric
edge_index = np.array(G.edges()).T
edge_index = torch.tensor(edge_index, dtype=torch.long)
# Assign valuations
public_valuations = np.random.uniform(100, 500, size=(NUM_PUBLIC, YEARS))
private_valuations = np.full((NUM_FIRMS - NUM_PUBLIC, YEARS), np.nan)
valuations = np.vstack([public_valuations, private_valuations])
# Combine features (excluding liquidity discounts and control premiums)
combined_features = torch.tensor(time_series_data, dtype=torch.float32)
Firm Generation: Creates a mix of public and private firms, each assigned to an industry.
Time Series Data: Simulates historical features (e.g., financial metrics) for each firm.
Network Connections: Models relationships between firms within the same industry using a random graph.
Valuations: Assigns known valuations to public firms and NaN to private firms.
Features Combination: Prepares the data for model input, excluding user-defined factors like liquidity discounts.
Model Components#
Define a neural network architecture that combines GNNs and LSTMs to process both relational (graph-based) and temporal (time series) data.
LSTM for Time Series Data#
class LSTMTimeSeries(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers=2):
super(LSTMTimeSeries, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
lstm_out, _ = self.lstm(x)
final_output = self.fc(lstm_out[:, -1, :]) # Last time step
return final_output
GNN with Time Series#
class GNNWithTimeSeries(nn.Module):
def __init__(self, graph_input_dim, graph_hidden_dim, graph_output_dim,
time_input_dim, time_hidden_dim, time_output_dim):
super(GNNWithTimeSeries, self).__init__()
# GNN layers
self.conv1 = GCNConv(graph_input_dim, graph_hidden_dim)
self.conv2 = GCNConv(graph_hidden_dim, graph_output_dim)
# LSTM layers
self.lstm = LSTMTimeSeries(time_input_dim, time_hidden_dim, time_output_dim)
# Final output layer
self.fc_final = nn.Linear(graph_output_dim, 1)
def forward(self, graph_features, time_features, edge_index):
# GNN forward pass
gnn_out = torch.relu(self.conv1(graph_features, edge_index))
gnn_out = self.conv2(gnn_out, edge_index)
# LSTM forward pass
lstm_out = self.lstm(time_features)
# Combine outputs
combined = gnn_out + lstm_out # Simple addition
output = self.fc_final(combined) # Scalar output
return output.squeeze()
LSTM Network:
Captures temporal dependencies in the time series data for each firm.
Outputs a representation of the firm’s historical performance.
GNN Network:
Processes graph-structured data, capturing the influence of connected firms.
Generates embeddings that reflect both a firm’s features and its relationships.
Combination and Output:
The outputs from the LSTM and GNN are combined.
A final linear layer maps the combined representation to a scalar valuation prediction.
Rationale: Integrated Modeling: Combining GNN and LSTM allows the model to consider both temporal trends and relational influences, providing a more comprehensive valuation estimate.
Compute Caps for Constraints#
Calculate industry-specific valuation caps for each firm to enforce realistic valuation predictions based on public firms.
def compute_caps(firm_ids, industries, valuations, growth_cap_multiplier):
caps = np.full(NUM_FIRMS, np.inf) # Initialize with infinity
for industry in range(NUM_INDUSTRIES):
peer_vals = valuations[(industries == industry) & is_public, -1]
if len(peer_vals) > 0:
max_peer = np.max(peer_vals)
cap = max_peer * growth_cap_multiplier
caps[industries == industry] = cap
return caps
# Compute caps and convert to tensor
caps = compute_caps(firm_ids, industries, valuations, GROWTH_CAP_MULTIPLIER)
caps_tensor = torch.tensor(caps, dtype=torch.float32)
Caps Calculation:
For each industry, identifies the maximum valuation among public firms.
Applies a growth multiplier (e.g., 1500%) to set the cap.
Assigns this cap to all firms within the same industry.
Rationale: Industry-Based Constraints:
Ensures that private firms’ valuations are within a reasonable range compared to their public peers.
Reflects market realities and prevents overestimation.
Training the GNN with Time Series (Modified)#
Train the neural network while applying the calculated valuation caps to enforce constraints during learning.
loss_history = []
def train_gnn_with_time_series(model, optimizer, criterion, graph_features, time_features, edge_index, valuations, caps_tensor, epochs=100):
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
output = model(graph_features, time_features, edge_index)
# Apply constraints
min_tensor = torch.zeros_like(output).to(caps_tensor.device)
output = torch.clamp(output.to(caps_tensor.device), min=min_tensor, max=caps_tensor)
# Compute loss on public firms
target = valuations[:, -1]
mask = ~np.isnan(target)
target = torch.tensor(target[mask], dtype=torch.float32).to(caps_tensor.device)
preds = output[mask]
loss = criterion(preds, target)
loss.backward()
optimizer.step()
loss_history.append(loss.item())
if (epoch+1) % 20 == 0 or epoch == 0:
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")
# Model Initialization and Training Execution:
# Initialize the model
GRAPH_INPUT_DIM = combined_features.shape[2] # Number of features per node
GRAPH_HIDDEN_DIM = 64
GRAPH_OUTPUT_DIM = 32
TIME_INPUT_DIM = FEATURES_PER_YEAR
TIME_HIDDEN_DIM = 64
TIME_OUTPUT_DIM = 32
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Initialize the model
model = GNNWithTimeSeries(
graph_input_dim=GRAPH_INPUT_DIM,
graph_hidden_dim=GRAPH_HIDDEN_DIM,
graph_output_dim=GRAPH_OUTPUT_DIM,
time_input_dim=TIME_INPUT_DIM,
time_hidden_dim=TIME_HIDDEN_DIM,
time_output_dim=TIME_OUTPUT_DIM
).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# Prepare features and move to device
graph_features = combined_features[:, -1, :].to(device)
time_features = combined_features.to(device)
edge_index = edge_index.to(device)
caps_tensor = caps_tensor.to(device)
# Train the model
train_gnn_with_time_series(
model,
optimizer,
criterion,
graph_features,
time_features,
edge_index,
valuations,
caps_tensor,
epochs=100
)
Epoch 1/100, Loss: 98073.0625
Epoch 20/100, Loss: 39097.5156
Epoch 40/100, Loss: 15472.0088
Epoch 60/100, Loss: 13259.4004
Epoch 80/100, Loss: 12701.3350
Epoch 100/100, Loss: 12305.6621
Applying Constraints:
Uses torch.clamp to enforce that predictions are between 0 and the cap.
Ensures that the model learns to produce valuations within acceptable bounds.
Loss Computation:
Calculates loss only on public firms since their true valuations are known.
Uses Mean Squared Error (MSE) as the loss function.
Training Loop:
Performs forward pass, backpropagation, and optimizer step.
Records loss for analysis.
Rationale
Constraint Enforcement During Training:
Helps the model to internalize the valuation limits.
Leads to more realistic predictions for private firms.
Focusing on Public Firms for Loss:
Since private firms’ valuations are unknown, training on public firms prevents introducing noise from uncertain targets.
Model Validation#
Evaluate the model’s predictive performance using standard regression metrics and visualize the results.
# Get model predictions and embeddings
model.eval()
with torch.no_grad():
all_preds = model(graph_features, time_features, edge_index)
# Ensure 'all_preds' and 'caps_tensor' are on the same device
all_preds = all_preds.to(caps_tensor.device)
# Create 'min_tensor' as zeros_like 'all_preds' on the same device
min_tensor = torch.zeros_like(all_preds).to(caps_tensor.device)
# Apply constraints to the output
all_preds = torch.clamp(all_preds, min=min_tensor, max=caps_tensor)
node_embeddings = all_preds.cpu().numpy()
def validate_model(preds, valuations):
target = valuations[:, -1]
mask = ~np.isnan(target)
target = target[mask]
preds = preds[mask]
# Evaluation metrics
mae = mean_absolute_error(target, preds)
mse = mean_squared_error(target, preds)
rmse = np.sqrt(mse)
r2 = r2_score(target, preds)
print(f"\nValidation Metrics:")
print(f"Mean Absolute Error (MAE): {mae:.4f}")
print(f"Root Mean Squared Error (RMSE): {rmse:.4f}")
print(f"R-squared (R2): {r2:.4f}")
# Plotting Predictions vs True Values
plt.figure(figsize=(8,6))
plt.scatter(target, preds, alpha=0.7)
plt.xlabel('True Valuations')
plt.ylabel('Predicted Valuations')
plt.title('Predicted vs True Valuations')
plt.plot([target.min(), target.max()], [target.min(), target.max()], 'k--', lw=2)
plt.show()
# Validate the model
validate_model(node_embeddings, valuations)
Validation Metrics:
Mean Absolute Error (MAE): 94.7107
Root Mean Squared Error (RMSE): 110.8526
R-squared (R2): 0.0866
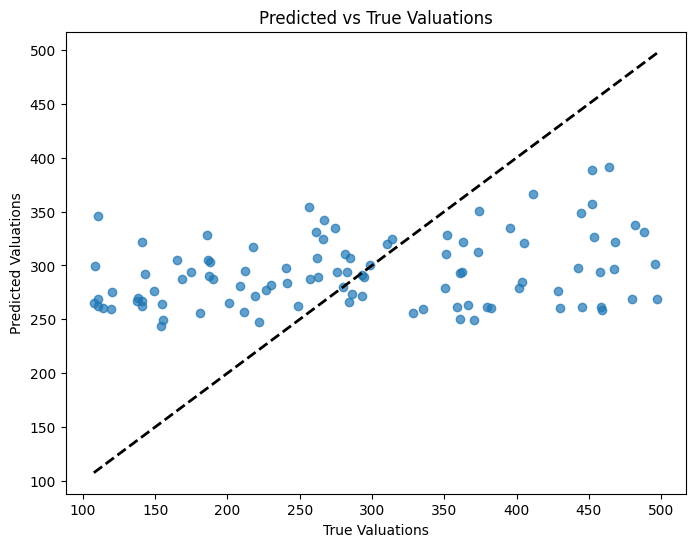
Metrics Computed:
MAE: Average absolute difference between predicted and true valuations.
RMSE: Square root of the average squared differences.
R² Score: Proportion of variance explained by the model.
Visualization:
Scatter plot of predicted vs. true valuations.
Diagonal line represents perfect predictions.
Rationale: Assessing Model Performance:
Metrics provide quantitative measures of accuracy.
Visualization helps identify patterns, biases, or outliers.
Plot Loss over Epochs#
Monitor the training process to ensure the model is learning effectively.
def plot_loss_history():
plt.figure(figsize=(8,6))
plt.plot(loss_history)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Time')
plt.show()
# Plot the loss
plot_loss_history()
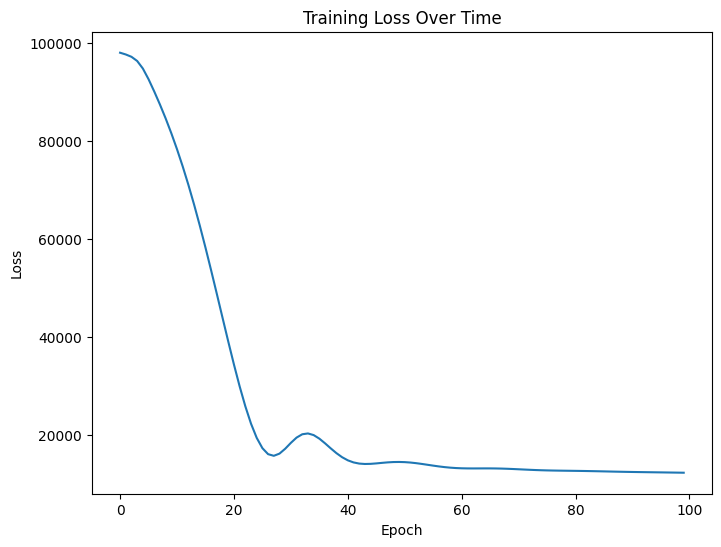
Loss Curve:
Displays how the loss decreases over epochs.
Helps identify issues like plateauing or increasing loss.
Rationale: Training Monitoring:
Ensures that the model is converging.
Provides insight into whether more epochs are needed or if overfitting is occurring.
LightGBM with Quantile Regression#
Estimate the lower and upper bounds of the firm’s valuation using quantile regression, providing a range rather than a single point estimate.
# Prepare features for LightGBM
X_combined = node_embeddings.reshape(-1, 1) # Use model predictions as features
y = valuations[:, -1]
# Split into training data (public firms only)
train_mask = ~np.isnan(y)
X_train = X_combined[train_mask]
y_train = y[train_mask]
# Function to train LightGBM quantile model
def train_lightgbm_quantile(X_train, y_train, quantile=0.5):
params = {
'boosting_type': 'gbdt',
'objective': 'quantile',
'metric': 'quantile',
'alpha': quantile,
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'verbose': -1,
}
lgb_train = lgb.Dataset(X_train, y_train)
model = lgb.train(params, lgb_train, num_boost_round=100)
return model
# Train quantile models
gbm_upper = train_lightgbm_quantile(X_train, y_train, quantile=0.9)
gbm_lower = train_lightgbm_quantile(X_train, y_train, quantile=0.1)
# Predict on all firms
y_pred_upper = gbm_upper.predict(X_combined)
y_pred_lower = gbm_lower.predict(X_combined)
Feature Preparation:
Uses the neural network’s predictions as the sole feature for LightGBM.
Focuses on capturing the relationship between the predicted valuations and the true valuations.
Quantile Regression:
Trains two models targeting different quantiles (e.g., 10th and 90th percentiles).
The alpha parameter in LightGBM specifies the quantile to estimate.
Rationale:
Why Quantile Regression with LightGBM?
Uncertainty Estimation:
Provides a range for valuations, acknowledging the inherent uncertainty in predictions.
Helps in risk assessment by offering lower and upper bounds.
Non-parametric Approach:
LightGBM is a gradient boosting framework that can model complex nonlinear relationships without assuming a specific data distribution.
Suitable for capturing patterns that neural networks might have missed.
Complementary to Neural Networks:
While neural networks provide a point estimate, LightGBM quantile regression refines this estimate by learning from residual errors.
Leverages the strengths of both models for better prediction intervals.
Choice of LightGBM:
Efficiency: LightGBM is known for its speed and efficiency, especially with large datasets.
Flexibility: Supports quantile regression out of the box, making it convenient for estimating different quantiles.
Handling Overfitting: Features built-in mechanisms like early stopping and regularization to prevent overfitting.
Applying Constraints (Adjusted)#
Ensure the LightGBM predictions adhere to the same valuation caps applied during neural network training.
# Apply constraints to LightGBM predictions
bounded_lower = np.maximum(y_pred_lower, 0)
bounded_upper = y_pred_upper.copy()
for i in range(NUM_FIRMS):
cap = caps[i]
bounded_upper[i] = min(bounded_upper[i], cap)
Lower Bound: Ensures that the lower bound predictions are not negative.
Upper Bound: Caps the upper bound predictions using the previously calculated industry-specific caps.
Rationale: Consistency in Constraints:
Maintains the integrity of the valuation estimates across different modeling stages.
Prevents unrealistic valuation ranges.
Final Output#
Consolidate all results and present them in an accessible format for analysis or reporting.
# Create a DataFrame to display results
results = pd.DataFrame({
'Firm_ID': firm_ids,
'Industry': industries,
'Is_Public': is_public,
'Predicted_Lower_Bound': y_pred_lower,
'Predicted_Upper_Bound': y_pred_upper,
'Bounded_Lower': bounded_lower,
'Bounded_Upper': bounded_upper,
'Adjusted_Lower': adjusted_lower,
'Adjusted_Upper': adjusted_upper
})
# Display the first 10 results
print("\nFinal Valuation Results:")
print(results.head(10))
Final Valuation Results:
Firm_ID Industry Is_Public Predicted_Lower_Bound Predicted_Upper_Bound \
0 0 3 True 165.911317 459.551847
1 1 1 True 189.568994 465.691175
2 2 1 True 189.568994 465.691175
3 3 2 True 190.704123 455.046583
4 4 0 True 120.030000 479.369185
5 5 1 True 189.568994 465.691175
6 6 2 True 119.672857 442.240551
7 7 0 True 111.687010 442.240551
8 8 1 True 111.687010 442.240551
9 9 2 True 119.672857 442.240551
Bounded_Lower Bounded_Upper Adjusted_Lower Adjusted_Upper
0 165.911317 459.551847 172.547770 477.933921
1 189.568994 465.691175 197.151754 484.318822
2 189.568994 465.691175 197.151754 484.318822
3 190.704123 455.046583 198.332288 473.248446
4 120.030000 479.369185 124.831200 498.543953
5 189.568994 465.691175 197.151754 484.318822
6 119.672857 442.240551 124.459772 459.930174
7 111.687010 442.240551 116.154490 459.930174
8 111.687010 442.240551 116.154490 459.930174
9 119.672857 442.240551 124.459772 459.930174
Possible Improvements#
Advanced Model Architectures:
Experiment with different GNN variants (e.g., Graph Attention Networks).
Explore more sophisticated methods of combining GNN and LSTM outputs.
Hyperparameter Optimization:
Use automated tools (e.g., Grid Search, Bayesian Optimization) to fine-tune model parameters.
Regularization and Overfitting Prevention:
Implement dropout layers, weight decay, and early stopping techniques.
Cross-Validation:
Employ k-fold cross-validation to assess the model’s generalization capability.
Uncertainty Quantification:
Utilize Bayesian neural networks or ensemble methods for better uncertainty estimation.
Model Interpretability:
Apply SHAP values or other explainability techniques to understand feature importance.