Risk Minimization#
#!pip install numpy pandas scikit-learn xgboost matplotlib seaborn
import numpy as np
import pandas as pd
# Set a random seed for reproducibility
np.random.seed(42)
# Number of samples
n_samples = 100
# Generate ovd_days (overdue days)
ovd_days = np.random.randint(0, 120, size=n_samples)
# Generate ovd30, ovd60, ovd90 based on ovd_days
ovd30 = np.where(ovd_days >= 30, np.random.uniform(100, 1000, size=n_samples), 0)
ovd60 = np.where(ovd_days >= 60, np.random.uniform(100, 1000, size=n_samples), 0)
ovd90 = np.where(ovd_days >= 90, np.random.uniform(100, 1000, size=n_samples), 0)
# Generate additional 16 features (e.g., income, age, credit score, etc.)
additional_features = {
f'feature_{i}': np.random.uniform(0, 1, size=n_samples)
for i in range(1, 17)
}
# Define the target variable 'default'
default = np.where(ovd_days >= 90, 1, 0)
# Create a DataFrame
data = pd.DataFrame({
'ovd_days': ovd_days,
'ovd30': ovd30,
'ovd60': ovd60,
'ovd90': ovd90,
'default': default
})
# Add additional features to the DataFrame
for feature_name, values in additional_features.items():
data[feature_name] = values
# Display the first few rows
print(data.head())
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[2], line 2
1 import numpy as np
----> 2 import pandas as pd
3
4 # Set a random seed for reproducibility
5 np.random.seed(42)
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/__init__.py:22
19 del _hard_dependencies, _dependency, _missing_dependencies
21 # numpy compat
---> 22 from pandas.compat import is_numpy_dev as _is_numpy_dev # pyright: ignore # noqa:F401
24 try:
25 from pandas._libs import hashtable as _hashtable, lib as _lib, tslib as _tslib
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/compat/__init__.py:18
15 from typing import TYPE_CHECKING
17 from pandas._typing import F
---> 18 from pandas.compat.numpy import (
19 is_numpy_dev,
20 np_version_under1p21,
21 )
22 from pandas.compat.pyarrow import (
23 pa_version_under1p01,
24 pa_version_under2p0,
(...) 31 pa_version_under9p0,
32 )
34 if TYPE_CHECKING:
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/compat/numpy/__init__.py:4
1 """ support numpy compatibility across versions """
2 import numpy as np
----> 4 from pandas.util.version import Version
6 # numpy versioning
7 _np_version = np.__version__
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/util/__init__.py:2
1 # pyright: reportUnusedImport = false
----> 2 from pandas.util._decorators import ( # noqa:F401
3 Appender,
4 Substitution,
5 cache_readonly,
6 )
8 from pandas.core.util.hashing import ( # noqa:F401
9 hash_array,
10 hash_pandas_object,
11 )
14 def __getattr__(name):
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/util/_decorators.py:14
6 from typing import (
7 Any,
8 Callable,
9 Mapping,
10 cast,
11 )
12 import warnings
---> 14 from pandas._libs.properties import cache_readonly
15 from pandas._typing import (
16 F,
17 T,
18 )
19 from pandas.util._exceptions import find_stack_level
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/_libs/__init__.py:13
1 __all__ = [
2 "NaT",
3 "NaTType",
(...) 9 "Interval",
10 ]
---> 13 from pandas._libs.interval import Interval
14 from pandas._libs.tslibs import (
15 NaT,
16 NaTType,
(...) 21 iNaT,
22 )
File pandas/_libs/interval.pyx:1, in init pandas._libs.interval()
----> 1 'Could not get source, probably due dynamically evaluated source code.'
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
import matplotlib.pyplot as plt
import seaborn as sns
# Check for missing values
print("Missing values in each column:")
print(data.isnull().sum())
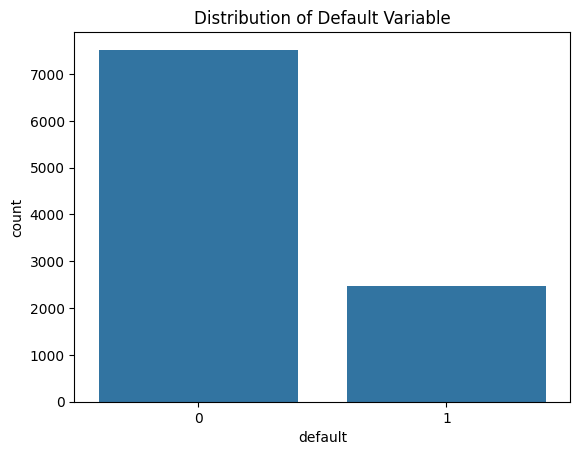
# Distribution of the target variable
sns.countplot(x='default', data=data)
plt.title('Distribution of Default Variable')
plt.show()
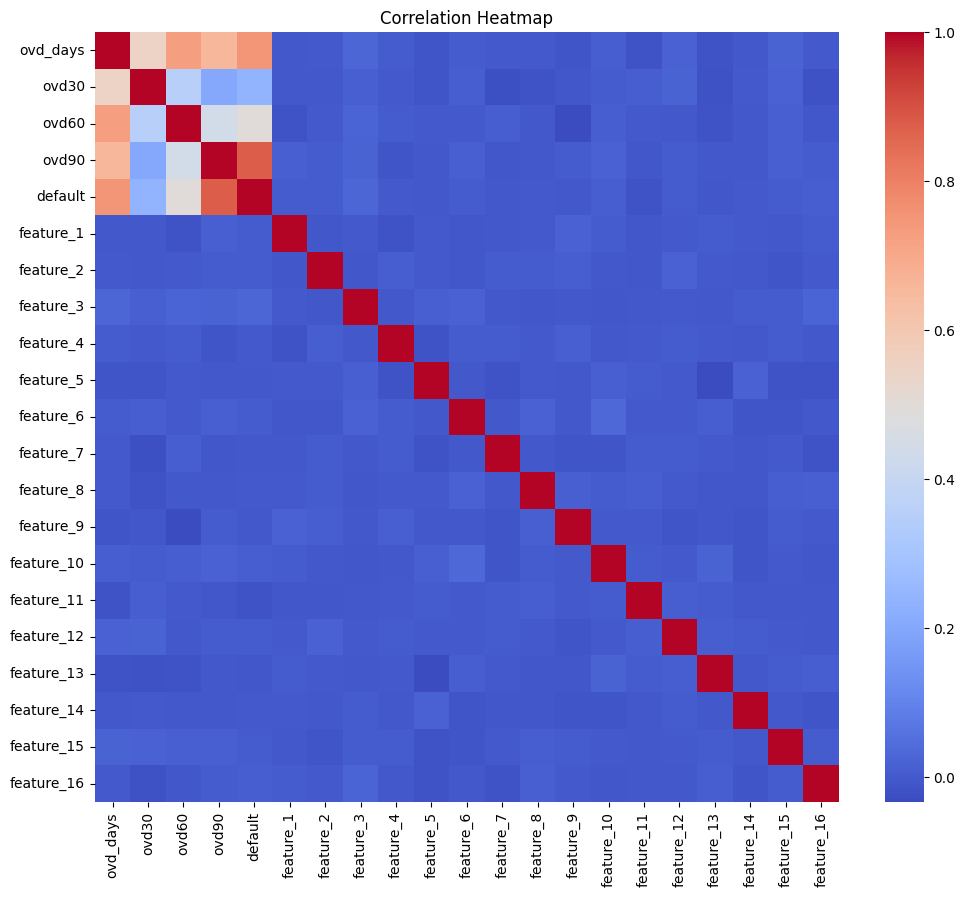
# Correlation heatmap
plt.figure(figsize=(12, 10))
sns.heatmap(data.corr(), cmap='coolwarm', annot=False)
plt.title('Correlation Heatmap')
plt.show()
Missing values in each column:
ovd_days 0
ovd30 0
ovd60 0
ovd90 0
default 0
feature_1 0
feature_2 0
feature_3 0
feature_4 0
feature_5 0
feature_6 0
feature_7 0
feature_8 0
feature_9 0
feature_10 0
feature_11 0
feature_12 0
feature_13 0
feature_14 0
feature_15 0
feature_16 0
dtype: int64
# Data Pre-processing
from sklearn.preprocessing import StandardScaler
# Separate features and target
X = data.drop('default', axis=1)
y = data['default']
# Feature Scaling
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split the dataset into training and testing sets.
from sklearn.model_selection import train_test_split
# Split the data (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
# !pip install xgboost
# building the model
import xgboost as xgb
from xgboost import XGBClassifier
# Initialize the model
model = XGBClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=5,
random_state=42,
# use_label_encoder=False,
eval_metric='logloss'
)
# Train the model
model.fit(X_train, y_train)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric='logloss',
feature_types=None, gamma=None, grow_policy=None,
importance_type=None, interaction_constraints=None,
learning_rate=0.1, max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None, max_depth=5,
max_leaves=None, min_child_weight=None, missing=nan,
monotone_constraints=None, multi_strategy=None, n_estimators=100,
n_jobs=None, num_parallel_tree=None, random_state=42, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric='logloss',
feature_types=None, gamma=None, grow_policy=None,
importance_type=None, interaction_constraints=None,
learning_rate=0.1, max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None, max_depth=5,
max_leaves=None, min_child_weight=None, missing=nan,
monotone_constraints=None, multi_strategy=None, n_estimators=100,
n_jobs=None, num_parallel_tree=None, random_state=42, ...)from sklearn.metrics import (
accuracy_score, confusion_matrix, classification_report, roc_auc_score, roc_curve
)
# Predictions on the test set
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# Accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
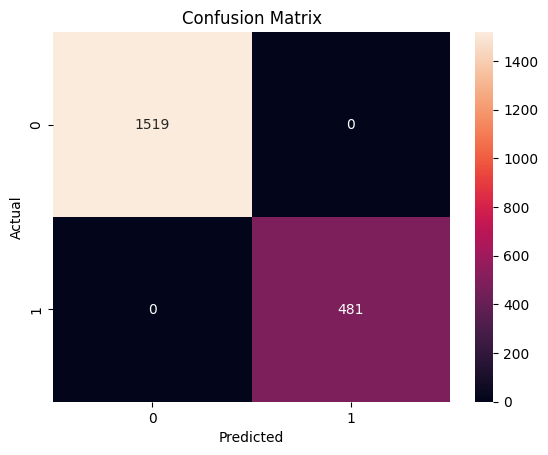
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
# Classification Report
print('Classification Report:')
print(classification_report(y_test, y_pred))
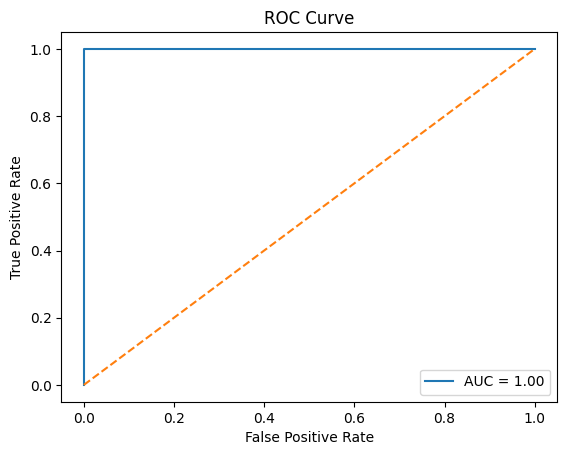
# ROC AUC Score
roc_auc = roc_auc_score(y_test, y_pred_proba)
print(f'ROC AUC Score: {roc_auc:.2f}')
# ROC Curve
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
plt.plot(fpr, tpr, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], linestyle='--')
plt.title('ROC Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend()
plt.show()
Accuracy: 1.00
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 1519
1 1.00 1.00 1.00 481
accuracy 1.00 2000
macro avg 1.00 1.00 1.00 2000
weighted avg 1.00 1.00 1.00 2000
ROC AUC Score: 1.00
Model Comparisons#
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# Generate synthetic data
np.random.seed(42)
n_samples = 1000
ovd_days = np.random.randint(0, 120, size=n_samples)
ovd30 = np.where(ovd_days >= 30, np.random.uniform(100, 1000, size=n_samples), 0)
ovd60 = np.where(ovd_days >= 60, np.random.uniform(100, 1000, size=n_samples), 0)
ovd90 = np.where(ovd_days >= 90, np.random.uniform(100, 1000, size=n_samples), 0)
additional_features = {f'feature_{i}': np.random.uniform(0, 1, size=n_samples) for i in range(1, 17)}
default = np.where(ovd_days >= 90, 1, 0)
# Create DataFrame
data = pd.DataFrame({'ovd_days': ovd_days, 'ovd30': ovd30, 'ovd60': ovd60, 'ovd90': ovd90, 'default': default})
for feature_name, values in additional_features.items():
data[feature_name] = values
# Splitting data into train, validation, and holdout sets
X = data.drop('default', axis=1)
y = data['default']
# Train-Validation-Holdout split (60-20-20)
X_train_full, X_holdout, y_train_full, y_holdout = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.25, random_state=42) # 0.25 x 0.8 = 0.2
print(f"Training set size: {X_train.shape[0]}")
print(f"Validation set size: {X_val.shape[0]}")
print(f"Holdout set size: {X_holdout.shape[0]}")
Training set size: 600
Validation set size: 200
Holdout set size: 200
#!pip install catboost
# Indivudal Models
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import xgboost as xgb
import lightgbm as lgb
from catboost import CatBoostClassifier
# Instantiate individual models
logistic_model = LogisticRegression(random_state=42)
decision_tree = DecisionTreeClassifier(random_state=42)
random_forest = RandomForestClassifier(n_estimators=100, random_state=42)
xgboost_model = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42, eval_metric='logloss')
lightgbm_model = lgb.LGBMClassifier(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)
catboost_model = CatBoostClassifier(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42, verbose=0)
# Stacking
# For stacking, we will combine the predictions of individual models using a meta-model.
from sklearn.ensemble import StackingClassifier
# Define base models for stacking
base_models = [
('logistic', logistic_model),
('decision_tree', decision_tree),
('random_forest', random_forest),
('xgboost', xgboost_model),
('lightgbm', lightgbm_model),
('catboost', catboost_model)
]
# Meta-model: Logistic Regression
meta_model = LogisticRegression(random_state=42)
# Stacking Classifier
stacking_model = StackingClassifier(estimators=base_models, final_estimator=meta_model, cv=5)
# Training all models
models = {
"Logistic Regression": logistic_model,
"Decision Tree": decision_tree,
"Random Forest": random_forest,
"XGBoost": xgboost_model,
"LightGBM": lightgbm_model.set_params(verbose=-1), # Set verbose to -1 to silence output
"CatBoost": catboost_model,
"Stacking Model": stacking_model
}
# Train each model on the training set
for name, model in models.items():
print(f"Training {name}...")
model.fit(X_train, y_train)
Training Logistic Regression...
Training Decision Tree...
Training Random Forest...
Training XGBoost...
Training LightGBM...
Training CatBoost...
Training Stacking Model...
# !pip install ace_tools
from sklearn.metrics import accuracy_score, roc_auc_score, precision_score, recall_score
def evaluate_model(model, X, y):
"""
Evaluate the model on the given dataset and return various performance metrics.
Parameters:
- model: Trained model to evaluate
- X: Feature matrix
- y: True labels
Returns:
- accuracy: Accuracy score of the model
- roc_auc: ROC AUC score
- precision: Precision score
- recall: Recall score
"""
predictions = model.predict(X)
proba = model.predict_proba(X)[:, 1] # Probability estimates for the positive class
accuracy = accuracy_score(y, predictions)
roc_auc = roc_auc_score(y, proba)
precision = precision_score(y, predictions)
recall = recall_score(y, predictions)
return accuracy, roc_auc, precision, recall
# Evaluating models on the validation set
validation_results = pd.DataFrame(columns=["Model", "Accuracy", "ROC AUC", "Precision", "Recall"])
for name, model in models.items():
accuracy, roc_auc, precision, recall = evaluate_model(model, X_val, y_val)
result = pd.DataFrame({
"Model": [name],
"Accuracy": [accuracy],
"ROC AUC": [roc_auc],
"Precision": [precision],
"Recall": [recall]
})
validation_results = pd.concat([validation_results, result], ignore_index=True)
# Evaluate each model on the holdout set
holdout_results = pd.DataFrame(columns=["Model", "Accuracy", "ROC AUC", "Precision", "Recall"])
for name, model in models.items():
accuracy, roc_auc, precision, recall = evaluate_model(model, X_holdout, y_holdout)
result = pd.DataFrame({
"Model": [name],
"Accuracy": [accuracy],
"ROC AUC": [roc_auc],
"Precision": [precision],
"Recall": [recall]
})
holdout_results = pd.concat([holdout_results, result], ignore_index=True)
# Display holdout results
print(holdout_results)
Model Accuracy ROC AUC Precision Recall
0 Logistic Regression 1.0 1.0 1.0 1.0
1 Decision Tree 1.0 1.0 1.0 1.0
2 Random Forest 1.0 1.0 1.0 1.0
3 XGBoost 1.0 1.0 1.0 1.0
4 LightGBM 1.0 1.0 1.0 1.0
5 CatBoost 1.0 1.0 1.0 1.0
6 Stacking Model 1.0 1.0 1.0 1.0